Object Oriented Programming¶
Note
Even Python is intrinsically object oriented (in python every things we manipulate are objects) it is a multi paradigm language. It means that Python allow us to program in procedural, functional or oriented-object style, or any mixture of styles (in opposite of java which force you to adopt oriented object style).
Until now we use procedural style, and it’s very convenient to program small programs (up to 500 lines). But for medium and large size programs, object-oriented offer some advantages.
Before we dig deeper into modeling with objects, a word on models in general. Modeling is an abstracting activity motivated by a particular need or goal. We model in order to bring specific facets of an unruly domain into a space where they can be structured and manipulated. There are no natural representations of the world the way it “really is,” just many purposeful selections, abstractions, and simplifications, some of which are more useful than others for satisfying a particular goal. Object oriented programming is a way to modeling our problem using Objects.
Why to use Objects?
as us some question.
What is a good program?
- a program which do what we expected,
- run fast
- ease to use
- ease to extend
these criteria can be qualified as “external” but there are some other criteria that we can qualified as “internal” such as
- ease to read the code
- modular
- ease to maintain
at the end the most important are the external criteria, but the way to obtain these external criteria is to fulfill the internal criteria.
Below some aspects that the oriented object programming aim to address.
- correctness: the capacity for a program to do the right job as defined by it’s specification.
- robustness: the capacity for a program to react well in in abnormal conditions
- extensibility: the easiness to add new features (new specifications) to a program
- reusability: the capacity to reuse some components for other different programs.
few words about the software maintenance
The maintenance is what happen after that a software is released. We usually focused on the development phase. But we usually admit that 70% of a software cost is due to it’s maintenance, which include several kinds of activities: bug fixes but also modification according to external change (eg new data format), new features ask by users, …
If we develop a software which deal with sequences a s input, and a new sequence format is created, we would like that our software handle this new format. We will have to modify our program. The problem is not that a part of the program know the data structure, it’s unavoidable as it as to treat these data. But with old traditional way this knowledge is scattered in too many parts of the system, which lead to change too many parts of the program. The theory of abstract data type (see further) provided us a key to address this issue.
Theoretically, in order to get a program that performs a given task and solves the problem you have specified, a basic set of instructions such as: branching, repetitions, expressions and data structures can be sufficient. Now, the programs that you produce can become a problem by themselves, for several reasons:
- They can become very large, resulting in thousand lines of code where it is becoming difficult to make even a slight change (extensibility problem).
- When an application is developped within a team, it is important for different people to be able to share the code and combine parts developped by different people (compatibility) ; having big and complex source files can become a problem.
- During your programmer’s life, or within a team, you will very often have to re-use the same kind of instructions set: searching for an item in a collection, organizing a hierarchical data structure, converting data formats, …; moreover, such typical blocks of code have certainly already been done elsewhere (reusability).
Generally, source code not well designed for re-use can thus be a problem. So, depending on the context of the project, there are some issues which are just related to the management of source code by humans, as opposed to the specification of the task to perform. And if you think about it, you probably tend to use variable names that are relevant to your data and problem, aren’t you? So, why? This is probably not for the computer, but, of course, rather for the human reader. So, in order to handle source structure and management issues, several conceptual and technical solutions have been designed in modern programming languages. This is the topic of this chapter.
Let us say that we have to develop source code for a big application and that we want this source code to be spread and shared among several team members, to be easy to maintain and evolve (extensible), and to be useful outside of the project for other people (reusable). What are the properties a source code should have for these purpose?
- it should be divided in small manageable chunks
- these chunks should be logically divided
- they should be easy to understand and use
- they should be as independant as possible: you should not have to use chunk A each time you need to use chunk B
- they should have a clear interface defining what they can do
The most important concept to obtain these properties is called modularity, or how to build modular software components. The general idea related to software components is that an application program can be built by combining small logical building blocks. In this approach, as shown in figure Figure 19.1, building blocks form a kind of high-level language.
Modularity¶
The simplest form of modularity is actually something that you already know: writing a function to encapsulate a block of statements within a logical unit, with some form of generalization, or abstraction, through the definition of some parameters. But there are more general and elaborated forms of components, namely: modules and packages. So, what is modularity? As developped in [Meyer97], modularity is again not a general single property, but is rather described by a few principles:
- A few interfaces: a component must communicate with as few other components as possible. The graph of dependencies between components should be rather loosely coupled.
- Small interfaces: whenever two components communicate, there should be as few communication as possible between them.
- Explicit interfaces: interfaces should be explicit. Indirect coupling, in particular through shared variables, should be made explicitly public.
- Information hiding: information in a component should generally remain private, except for elements explicitly belonging to the interface. This means that it should not be necessary to use non public attributes elements of a component in order to use it. In languages such as Python, as we will see later, it is technically difficult to hide a component’s attributes. So, some care must be taken in order to document public and private attributes.
- Syntactic units: Components must correspond to syntactic units of the language. In Python, this means that components should correspond to known elements such as modules, packages, classes, or functions that you use in Python statements:
import dna
from Bio.Seq import Seq
dna, Bio, Bio.Seq and Seq are syntactic units, not only files, directories or block of statements. In fact, Python really helps in defining components: almost everything that you define in a module is a syntactic unit. You can view this approach as though not only the user of the application would be taken into account, but also the programmer, as the user of an intermediate level product. This is why there is a need for interfaces design also at the component level.
Reusability¶
Programming is by definition a very repetitive task, and programmers have dreamed a lot of being able to pick off-the-shelves general purpose components, relieving them from this burden of programming the same code again and again. However, this objective has, by far, not really been reached so far. There are several both non technical and technical reasons for this. Non-technical reasons encompass organisational and psychological obstacles: although this has probably been reduced by the wide access to the Web, being aware of existing software, taking the time to learn it, and accepting to use something you don’t have built yourself are common difficulties in reusing components. On the technical side, there are some conditions for modules to be reusable.
- Flexibility: One of the main difficulty for making reusable components lies in the fact that, while having the impression that you are again programming the same stereotyped code, one does not really repeat exactly the same code. There are indeed slight variations that typically concern to following aspects (for instance, in a standard table lookup): types: the exact data type being used may vary: the table might contain integers, strings, …
- data structures and algorithms may vary: the table might be implemented with an array, a dictionary, a binary search tree, … ; the comparison function in the sort procedure may also vary according to the type of the items. So, as you can understand from these remarks, the more flexible the component is, the more reusable it is. Flexibility can be partly obtained by modularity, as long as modules are well designed. However, in order to get real flexibility, other techniques are required, such as genericity, polymorphism, or inheritance, t
- Independancy towards the internal representation: by providing a interface that does not imply any specific internal data structure, the module can be used more safely. The client program will be able to use the same interface, even if the internal representation is modified.
- Group of related objects: it is easier to use components when all objects that should be used together (the data structures, data and algorithms) are actually grouped in the same component.
- Common features: common features or similar templates among different modules should be made shareable, thus making the whole set of modules more consistent.
Abstract Data Types¶
What is an abstract data type? Well, a data type is what we have just presented at the fist day of this course in Python, as in many object-oriented language, it is a class. So, why abstract? One of the main objectives in component building, is to provide components that a programmer (you, your colleagues, or any programmer downloading your code) can be confident in. In order to get this programmer, who is a client of your code, confident into your class, you have to make it as stable as possible, and the best method to get a stable class is to define it at a level where no implementation decision is visible. In other words, defining a class should consist in defining a data type providing some abstract services, whose interface are clearly defined in term of parameters and return value and potential side effects. The advantages of this approach are the following:
- The implementor of the class can change the implementation for maintenance, bug fixes or optimization reasons, without disturbing the client code.
- The data type is defined as a set of high-level services with a semantic contract defining both the output that is provided and the input that is required from the client. This actually correspond to the general definition of a type in programming: a type is defined as a set of possible values and a set of operations available on these values.
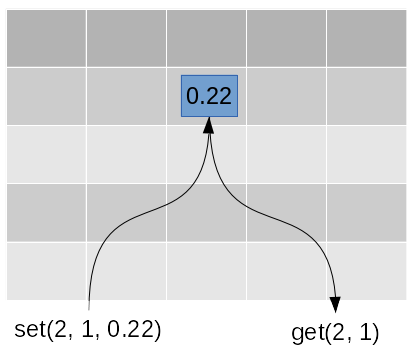
Among the methods defined in the interface of a data type, there are methods that build or change the state of the corresponding object, which are called constructors and modificators, and there are methods to access the object, which are called accessors. [ieb]
Example: A Matrix
As we already saw in Exercise about matrix.
Conceiving an abstract data type (ADT) for the stack consists in describing the functions needed making abstraction of the implementation choice that will be made at the end (and that may change). For instance, you might use a python list or dict or mix of list and dict. Will you add elements in list or dict? This concrete decision is out of concern for the user of your matrix, who should be taken away from knowing about this. Indeed in all cases, the basic services are the same, and can be given common names, that do not “betray” how the list is used “inside” of the code. The set of services is listed in Exercise
The description provided should suffice for the client to use the class. What is more important here, is that the client does not have to know anything about the internal representation of the matrix.
Concepts and Terminology¶
What is an Object ?¶
In programming an object is a concept. Calling elements of our programs objects is a metaphor, a useful way of thinking about them. In Python the basic elements of programming are things like strings, dictionaries, integers, functions, and so on … They are all objects. This means they have certain things in common.
In previous chapter we use the procedural style of programming. This divides your program into reusable ‘chunks’ called procedures or functions.
As much as possible you try to keep your code in these modular chunks using logic to decide which chunk is called. This makes it less mental strain to visualise what your program is doing. It also makes it easier to maintain your code. you can see which parts does what job. Improving one function (which is reused) can improve performance in several places of your program.
Data Separation¶
The procedural style of programming maintains a strict separation between your code and your data. You have variables, which contain your data, and procedures. You pass your variables to your procedures, which act on them and perhaps modify them.
If a function wants to modify the contents of a variable by passing it to another function it needs access to both the variable and the function it’s calling. If you’re performing complex operations this could be lots of variables and lots of functions.
But It turns out that lots of operations are common to objects of the same type. For example most languages have built in ways to create a lowercase version of a string. There are lots of standard operations that are associated only with strings. These include making a lowercase version, making an uppercase version, splitting the string up, and so on. In an object oriented language we can build these in as properties of the string object. In Python we call these methods.
Every string object has a standard set of methods, some of which you’ve probably already used.
an Object is an entity which contains data, AND procedures (code, functions, etc.). Data inside an object is called a data attribute. Functions, or procedures inside the object are called methods.
Encapsulation¶
As you can see objects combine data and the methods used to work with the data. This means it’s possible to wrap complex processes - but present a simple interface to them. How these processes are done inside the object becomes a mere implementation detail. Anyone using the object only needs to know about the public methods and attributes. This is the real principle of encapsulation. Other parts of your application (or even other programmers) can use your classes and their public methods, but you can update the object without breaking the interface they use.
You can also pass around objects instead of just data. This is one of the most useful aspects of object oriented programming. Once you have a reference to the object you can access any of the attributes of the object. If you need to perform a complex group of operations as part of a program you could probably implement it with procedures and variables. You might either need to use several global variables for storing state (which are slower to access than local variables and not good if a module needs to be reusable within your application) or your procedures might need to pass around a lot of variables.
If you implement a single class that has lots of attributes representing the state of your application, you only need to pass around a reference to that object. Any part of your code that has access to the object, can also access its attributes.
The main advantage of objects though is that it is a useful metaphor. It fits in with the way we think. In real life objects have certain properties and interact with each other. The more our programming language fits in with our way of thinking, the easier it is to use it to think creatively. but object need to help us to solve computing problems, they does not need to modelize an real life object. It need to have only properties and behaviors that we need in our program, for instance if I work with proteins in a 3D structure project, I will surely modelize my protein with the coordinates of each atoms that compose it, But if I need to search sequence similarities I will need only the amino acid sequence.
An object can also modelize an non real life object. For instance a parser there is no equivalent object in our lives but we need a parser to read a file in fasta format and create a sequence object so we can modelize a parser, idem with a database connection it’s not real life object but it’s very useful to think a connection as an object with properties like the port of the connection, the host of destination, … and some behaviors: connect, disconnect …
The object is very simple idea in the computing world. The objects allow us to organize code in a programs and cut things in small chunk to ease thinking about complexes ideas.
Classes¶
A class definition can be compared to the recipe to bake a cake. A recipe is needed to bake a cake. The main difference between a recipe (class) and a cake (an instance or an object of this class) is obvious. A cake can be eaten when it is baked, but you can’t eat a recipe, unless you like the taste of printed paper. Like baking a cake, an OOP program constructs objects according to the class definitions of the program program. A class contains variables and methods. If you bake a cake you need ingredients and instructions to bake the cake.
In python lot of people use class, data type and type interchangeably.
to create a custom class we have to use the keyword class followed by the name of the class the code belonging to a class in in the same block of code (indentation).
class ClassName:
suite
class Sequence:
code ...
some positional or keyword parameters can be add between parenthesis (we will see below the meaning of these parameters)
class ClassName(base_classes, meta=MyMetaClass):
suite
Note
pep 8: Class names should normally use the CapWords convention.
Objects¶
A class is a model, a template, an object is an instance of this model. If I use the metaphor of the cake and the recipe. You bake to cakes by following a recipe. the class is the recipe, you have two objects, the two cakes which are the instance of the same recipe. each cake have been made with the same ingredients but there are two independent cakes, a part of the first can be eaten whereas the second is still in the fridge.
# the model
class Cake:
pass
# apple_pie is an instance of Cake
apple_pie = Cake()
type(apple_pie)
<class '__main__.Cake'>
# pear_pie is an instance of Cake
pear_pie = Cake()
type(pear_pie)
<class '__main__.Cake'>
apple_pie is pear_pie
False
Attributes¶
Data attributes (often called simply attributes) are references to the data associated to an object. They are two kinds of attributes: instance variables, or class variables. An instance variables is directly associated to a particular object whereas a class variable is associated to a class then all objects which are instances of this class share the same variables (to more details see section about environments). We will not encounter lot of class variables. We can access to instance variable by its fully qualified name using the name of the instance and the name of attribute separated by a dot. We can access to the class variables using the fully qualified name through the class or through the instances of this class.
Objects are mutable You can change the state of an object by making an assignment to one of its attributes.:
class Sequence:
alpahbet = 'ATGC'
def __init__(self, seq):
"""
:param seq: the sequence
:type seq: string
"""
self.sequence = seq
ecor_1 = Sequence('GAATTC')
bamh_1 = Sequence('GGATCC')
print(ecor_1.sequence)
'GAATTC'
print(bamH_1.sequence)
'GGATCC'
print(Sequence.alphabet)
'ATGC'
print(ecor_1.alphabet)
'ATGC'
print(bamh_1.alphabet)
'ATGC'
ecor_1 is bamh_1
False
ecor_1.alphabet is bamh_1_1.alphabet
True
Sequence.alphabet = 'ATGCN'
print(ecor_1.alphabet)
'ATGCN'
Methods¶
In python methods a just attributes. But they are attributes which can be executed, in python we said callable. a method is bound to an object that mean this function is evaluated in the namespace of the object (see further).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | from __future__ import print_function
import string
class Sequence:
# the order of the nucleotide in alphabet is important
# to compute easily the reverse complement
alphabet = 'AGCT'
def __init__(self, seq):
"""
:param seq: the sequence
:type seq: string
"""
self.sequence = seq
def reverse_comp(self):
"""
:return: the reverse complement of this sequence
:rtype: :class:`Sequence` instance
"""
rev = self.sequence[::-1]
# the following syntax is for python2
table = string.maketrans(self.alphabet, self.alphabet[::-1])
rev_comp = string.translate(rev, table)
# in python3 maketrans and translate are not anymore a string module functions
# they are a str static methods
# table = str.maketrans(self.alphabet, self.alphabet[::-1])
# rev_comp = str.translate(rev, table)
return Sequence(rev_comp)
my_seq = Sequence('GAATTCC')
rev_comp = my_seq.reverse_comp()
print(my_seq.sequence)
print(rev_comp.sequence)
|
You may have notices the self parameter in function definition inside the class. But we called the method simply as ob.func() without any arguments. It still worked. This is because, whenever an object calls its method, the object itself is pass as the first argument. So, my_seq.reverse_comp() translates into Sequence.reverse_comp(my_seq). In general, calling a method with a list of n arguments is equivalent to calling the corresponding function with an argument list that is created by inserting the method’s object before the first argument. For these reasons, the first argument of the function in class must be the object itself. This is conventionally called self. It can be named otherwise but we highly recommend to follow the convention.
special methods¶
A class can implement certain operations that are invoked by special syntax (such as arithmetic operations or subscripting and slicing) by defining methods with special names. This is Python’s approach to operator overloading, allowing classes to define their own behavior with respect to language operators.
One of the biggest advantages of using Python’s magic methods is that they provide a simple way to make objects behave like built-in types. That means you can avoid ugly, counter-intuitive, and nonstandard ways of performing basic operators. In some languages, it’s common to do something like this:
if my_obj.equals(other_obj):
# do something
You could certainly do this in Python, too, but this adds confusion and is unnecessarily verbose. Different libraries might use different names for the same operations, making the client do way more work than necessary. With the power of magic methods, however, we can define one method (__eq__, in this case), and say what we mean instead:
if instance == other_instance:
#do something
The specials methods are defined by the language. They’re always surrounded by double underscores. There are a ton of special functions in Python.
Overloading the + Operator¶
To overload the + sign, we will need to implement __add__() function in the class. With great power comes great responsibility. We can do whatever we like, inside this function. But it is sensible to return a Point object of the coordinate sum.
class Point:
# previous definitions...
def __add__(self,other):
x = self.x + other.x
y = self.y + other.y
return Point(x,y)
Now let’s try that addition again.
>>> p1 = Point(2,3)
>>> p2 = Point(-1,2)
>>> print(p1 + p2)
(1,5)
Overloading Comparison Operators in Python¶
Python does not limit operator overloading to arithmetic operators only. We can overload comparison operators as well. Suppose, we wanted to implement the less than symbol < symbol in our Point class. Let us compare the magnitude of these points from the origin and return the result for this purpose. It can be implemented as follows.:
class Point:
# previous definitions...
def __lt__(self,other):
self_mag = (self.x ** 2) + (self.y ** 2)
other_mag = (other.x ** 2) + (other.y ** 2)
return self_mag < other_mag
Some sample runs.:
>>> Point(1,1) < Point(-2,-3)
True
>>> Point(1,1) < Point(0.5,-0.2)
False
>>> Point(1,1) < Point(1,1)
False
http://www.programiz.com/python-programming/operator-overloading
Comparison magic methods¶
Python provide a set of special methods to compare object:
- __eq__(self, other)
- Defines behavior for the equality operator, ==.
- __ne__(self, other)
- Defines behavior for the inequality operator, !=.
- __lt__(self, other)
- Defines behavior for the less-than operator, <.
- __gt__(self, other)
- Defines behavior for the greater-than operator, >.
- __le__(self, other)
- Defines behavior for the less-than-or-equal-to operator, <=.
- __ge__(self, other)
- Defines behavior for the greater-than-or-equal-to operator, >=.
http://www.python-course.eu/python3_magic_methods.php
Warning
Python2 provide the __cmp__ special method which allow to compare objects, but this special method disappear in python 3, use instead __eq__ , __ne__, __gt__, __lt__, …
- __cmp__(self, other)
__cmp__ is the most basic of the comparison magic methods. It actually implements behavior for all of the comparison operators (<, ==, !=, etc.), but it might not do it the way you want (for example, if whether one instance was equal to another were determined by one criterion and whether an instance is greater than another were determined by something else). __cmp__ should return a negative integer if self < other, zero if self == other, and positive if self > other. It’s usually best to define each comparison you need rather than define them all at once, but __cmp__ can be a good way to save repetition and improve clarity when you need all comparisons implemented with similar criteria.
Python 2.7.10 (default, Nov 26 2015, 15:03:27) [GCC 4.9.3] on linux2 Type “help”, “copyright”, “credits” or “license” for more information. >>> >>> class A(object): … def __init__(self, x): … self.x = x … def __cmp__(self, other): … return other.x - self.x … >>> a = A(2) >>> b = A(3) >>> a == b my cmp False >>> a > b my cmp True >>> b > a my cmp False
Python 3.4.3 (default, Jan 13 2016, 16:30:52) [GCC 4.9.3] on linux Type “help”, “copyright”, “credits” or “license” for more information. >>> >>> class A: … def __init__(self,x): … self.x = x … def __cmp__(self,oth): … print(“my_cmp”) … return oth.x - self.x … >>> >>> a=A(2) >>> b=A(3) >>> >>> a == 2 False >>> a > b Traceback (most recent call last):
File “<stdin>”, line 1, in <module>TypeError: unorderable types: A() > A() >>> a < b Traceback (most recent call last):
File “<stdin>”, line 1, in <module>TypeError: unorderable types: A() < A() >>>
__init__ method¶
To create an object, two steps are necessary. First a raw or uninitialized object must be created, and then the object must be initialized, ready for use. Some object-oriented languages (such as C++ and Java) combine these two steps into one, but Python keeps them separate.
When an object is created (e.g., ecor_1 = Sequence(‘GAATTC’),
first the special method __new__() is called to create the object,
and then the special method __init__() is called implicitly to initialize it.
In practice almost every Python class we create will require us to
reimplement only the __init__() method, since default __new__() method is al-
most always sufficient and is automatically called if we don’t provide our own
__new__() method.
Although we can create an attribute in any method, it is a good practice
to do this in the the __init__ method. Thus It is easy to know what attributes have an object
without being to read the entire code of a class.:
class Sequence:
alphabet = 'ATGC'
def __init__(self, name, seq):
"""
:param seq: the sequence
:type seq: string
"""
self.name = name
self.sequence = seq
self.nucleic = True
for char in self.sequence:
if char not in self.alphabet:
self.nucleic = False
break
Namespace and attributes lookup¶
The LEGB rule (Local, Enclosing, Global, Built-in) still applied. But when a class is created a namespace is created. futhermore for each instance of this a class a new namespace corresponding to this instance is created. There exist a link between the namespace of the instance and the namespace of it’s corresponding class. for example:
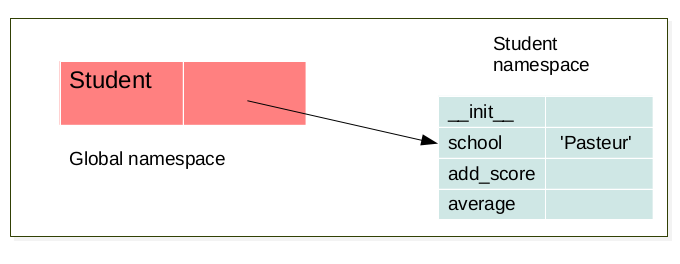
when a class is created a namespace is created.
class Student:
school = 'Pasteur'
def __init__(self, name):
self.name = name
self.scores = []
def add_score(self, val):
self.scores.append(val)
def average(self):
av = sum(self.scores)/len(self.scores)
return av
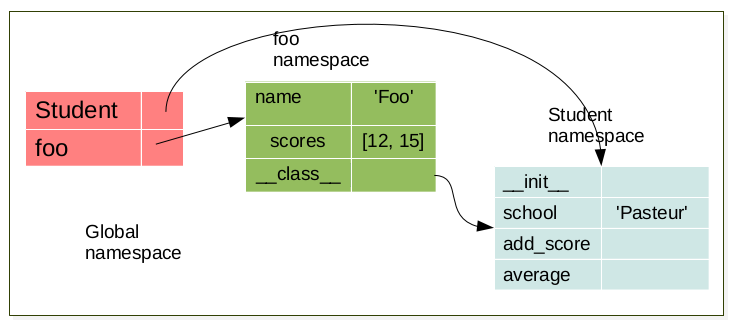
foo = Student('foo')
When an object is created, a namespace is created. This namespace is linked to its respective class namespace.
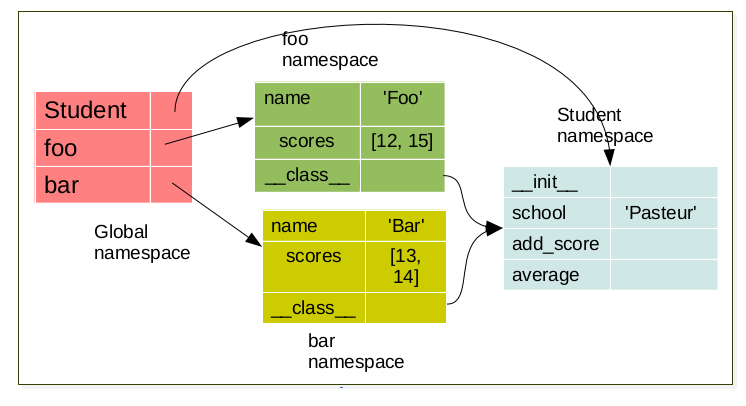
foo = Student('foo')
bar = Student('bar')
Each object have it’s own namespace which are linked to the class namespace.
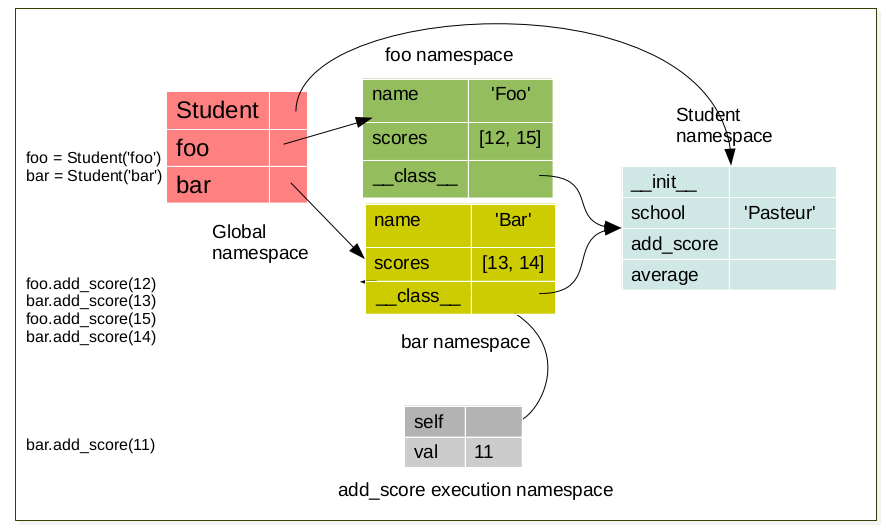
foo.add_score(12)
bar.add_score(13)
foo.add_score(15)
foo.add_score(14)
bar.add_score(11)
During method execution a namespace is created which have a link to the object instance. This namespace is destroyed a the end of the method (return)
To see it in action, you can play with the code below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from __future__ import print_function
class TestEnv:
class_att = 1
def __init__(self):
self.inst_att = 2
def test(self):
loc_var = 3
print("locals", locals())
print("globals", globals())
print("my self", self)
print("my class", self.__class__)
t = TestEnv()
t.test()
|
Control the access to the attributes¶
with underscore¶
“Private” instance variables that cannot be accessed except from inside an object don’t exist in Python. However, there is a convention that is followed by most Python code: a name prefixed with an underscore (e.g. _spam) should be treated as a non-public part of the API (whether it is a function, a method or a data member). It should be considered an implementation detail and subject to change without notice.
with double underscores¶
For private methods and functions, a leading underscore is conventionally added. This rule was quite controversial because of the name mangling feature in Python. When a method has two leading underscores, it is renamed on the fly by the interpreter to prevent a name collision with a method from any subclass. So some people tend to use a double leading underscore for their private attributes to avoid name collision in the subclasses:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | from __future__ import print_function
class Sequence:
__alphabet = 'ATGC'
def __init__(self, name, seq):
"""
:param seq: the sequence
:type seq: string
"""
self.name = name
self.__sequence = seq
def is_nucleic(self):
is_nucleic = True
for char in self.__sequence:
if char not in self.__alphabet:
is_nucleic = False
break
return is_nucleic
my_seq = Sequence('ecor1', 'GAATTC')
print(my_seq.is_nucleic())
print(my_seq.alphabet)
print(Sequence.alphabet)
print(my_seq._Sequence__alphabet)
|
The original motivation for name mangling in Python was not to provide a private gimmick like in C++, but to make sure that some base classes implicitly avoid collisions in subclasses, especially in multiple inheritance contexts. But using it for every attribute obfuscates the code in private, which is not Pythonic at all.
with property¶
The python way to control the access of attribute is using property() function. The purpose of this function is to create a property of a class. A property looks and acts like an ordinary attribute, except that you provide methods that control access to the attribute.
There are three kinds of attribute access: read, write, and delete. When you create a property, you can provide any or all of three methods that handle requests to read, write, or delete that attribute.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | class Sequence:
alphabet = 'ATGC'
def __init__(self, name, seq):
"""
:param seq: the sequence
:type seq: string
"""
self.name = name
self.sequence = seq
self.nucleic = True
for char in self.sequence:
if char not in self.alphabet:
self.nucleic = False
break
ecor1 = Sequence('ecor I', 'GAATTC')
ecor1.nucleic = False
|
The attribute nucleic can be modified. We don’t wish that any code outside the Sequence class can be set a new value for this attribute, it should be readable only. So we just have to transform nucleic as “private” and add a property to expose the value. We won’t provide a property to set a value or delete the attribute.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | class Sequence:
alphabet = 'ATGC'
def __init__(self, name, seq):
"""
:param seq: the sequence
:type seq: string
"""
self.name = name
self.sequence = seq
self.nucleic = True
for char in self.sequence:
if char not in self.alphabet:
self.nucleic = False
break
def get_nucleic(self):
return self._nucleic
nucleic = property(get_nucleic)
ecor1 = Sequence('ecor I', 'GAATTC')
ecor1.nucleic = False
|
above an other example where we use a getter and a setter. We want control that each coordinate a positive integer.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | class Coordinate:
def __init__(self, x, y):
self.set_coord(x, y)
def _check_coord(self, val):
return isinstance(int, val) and val >= 0
def get_coord(self):
return (self._x, self._y)
def set_coord(self, coord):
x, y = coord
if self._check_coord(x):
self._x = x
else:
raise ValueError("x must be a positive integer")
if self._check_coord(y):
self._y = y
else:
raise ValueError("y must be a positive integer")
coord = property(get_coord, set_coord)
a = Coordinate(2, 3)
a.coord
a.coord = (3, 4)
|
Here is the general method for adding a property named p to class C. where:
R is a getter method that takes no arguments and returns the effective attribute value. If omitted, any attempt to read that attribute will raise AttributeError.
W is a setter method that takes one argument and sets the attribute to that argument’s value. If omitted, any attempt to write that attribute will raise AttributeError.
D is a deleter method that deletes the attribute. If omitted, any attempt to delete that attribute will raise AttributeError.
But in most case you will see a shorter notation using decorators
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | class Coordinate
def __init__(self, x, y):
self.set_coord(x, y)
def _check_coord(self, val):
return isinstance(int, val) and val >=0
@property
def coord(self):
return (self._x, self._y)
@coord.setter
def coord(self, coord):
x, y = coord
if self._check_coord(x):
self._x = x
else:
raise ValueError("x must be a positive integer")
if self._check_coord(y):
self._y = y
else:
raise ValueError("y must be a positive integer")
a = Coordinate(2, 3)
a.coord
a.coord = 3, 4
|
deleting object¶
Any attribute of an object can be deleted anytime, using the del statement. We can even delete the object itself, using the del statement.
Actually, it is more complicated than that. When we do s1 = Sequence(‘ecor1’, ‘GAATTC’), a new instance object is created in memory and the name s1 binds with it. On the command del s1, this binding is removed and the name s1 is deleted from the corresponding namespace. The object however continues to exist in memory and if no other name is bound to it, it is later automatically destroyed. This automatic destruction of unreferenced objects in Python is also called garbage collection.
Exercises¶
Modelize a sequence with few attributes and methods
Exercise¶
Instanciate 2 sequences using your Sequence class, and draw schema representing the namespaces
Exercise¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | class MyClass(object):
class_attr = 'foo'
def __init__(self, val):
self.inst_attr = val
a = MyClass(1)
b = MyClass(2)
print a.inst_attr
print b.inst_attr
print a.class_attr == b.class_attr
print a.class_attr is b.class_attr
b.class_attr = 4
print a.class_attr
|
Can you explain this result (draw namespaces to explain) ? how to modify the class variable class_attr
Exercise¶
Write the definition of a Point class. Objects from this class should have a
- a method show to display the coordinates of the point
- a method move to change these coordinates.
- a method dist that computes the distance between 2 points.
Note
the distance between 2 points A(x0, y0) and B(x1, y1) can be compute
(http://www.mathwarehouse.com/algebra/distance_formula/index.php)
The following python code provides an example of the expected behaviour of objects belonging to this class:
>>> p1 = Point(2, 3)
>>> p2 = Point(3, 3)
>>> p1.show()
(2, 3)
>>> p2.show()
(3, 3)
>>> p1.move(10, -10)
>>> p1.show()
(12, -7)
>>> p2.show()
(3, 3)
>>> p1.dist(p2)
1.0
Exercise¶
Use OOP to modelize restriction enzyme, and sequences.
the sequence must implement the following methods
- enzyme_filter which take as a list of enzymes as argument and return a new list containing the enzymes which have binding site in sequence
the restriction enzyme must implements the following methods
- binds which take a sequence as argument and return True if the sequence contains a binding site, False otherwise.
solve the exercise Exercise using this new implementation.
Exercise¶
refactor your code of Exercise in OOP style programming. implements only
- size: return the number of rows, and number of columns
- get_cell: that take the number of rows, the number of columns as parameters, and returns the content of cell corresponding to row number col number
- set_cell: that take the number of rows, the number of columns as parameters, and a value and set the value val in cell specified by row number x column number
- to_str: return a string representation of the matrix
- mult: that take a scalar and return a new matrix which is the scalar product of matrix x val
you can change the name of the methods to be more pythonic
Exercise¶
Use the code to read multiple sequences fasta file in procedural style and refactor it in OOP style.
use the file abcd.fasta to test your code.
What is the benefit to use oop style instead of procedural style?