5. Collection Data Types¶
It is often convenient to hold entire collections of data items. Python provides several collection data types that can hold items. Each collection data type has properties which make it more suitable for some problems and less for others.
Some collection types are immutable and others are mutable. As we have seen in Variables chapter:
immutable objects are objects whose state cannot be changed. The collection is “frozen” after it’s creation. Of course we can access its items (and even modify them if they are mutable), but we cannot change the collection itself, for instance add, remove or reorder the collection.
mutable objects are objects whose state can be modified. We can access the items and we can modify the collection too: add, remove, change or sort items.
5.1. Sequence Types¶
A sequence type is one that supports the membership operator in,
the size function len, and slicing ([]) and is iterable
(i.e. it is possible to loop over its elements using a for statement,
something we will see later).
tuple, list, and string.collections.namedtuple.5.1.1. Tuples¶
A tuple is an immutable ordered sequence of zero or more object references.
5.1.1.1. Tuple creation¶
An empty tuple can be created with parentheses ():
>>> a = ()
>>> type(a)
<class 'tuple'>
A tuple with only one item is created with parentheses containing the item, followed by a coma, otherwise, we just obtain a new reference to the item itself:
>>> b = (1)
<class 'int'>
>>> b = (1,)
>>> type(b)
<class 'tuple'>
To create a tuple with more items, the items should be separated with commas. In that case, parentheses are optional:
>>> c = (1, 2)
>>> type(c)
<class 'tuple'>
>>> c = 1, 2
>>> type(c)
<class 'tuple'>
>>> c
(1, 2)
The tuple data type can be called as a function, tuple.
Without any argument, it returns an empty tuple:
>>> tuple()
()
With a tuple as argument, it returns a reference to the same tuple:
>>> t1 = 1, 2, "foo"
>>> print(t1)
(1, 2, 'foo')
>>> t2 = tuple(t1)
>>> print(t2)
(1, 2, 'foo')
>>> t1 is t2
True
With any other argument, it attempts to convert the given object into a tuple:
>>> tuple("ESWN")
('E', 'S', 'W', 'N')
This is not always possible:
>>> tuple(42)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
Tuple creation: what happens in memory.

Python creates three objects: two integers one string.
Python creates a tuple with three “slots”.
Each slot refers to one object, in the same order they have been “declared”.
The object reference
t1is created and references the tuple object.

5.1.1.2. Tuples as sequence types¶
Standard capabilities of sequence types work as expected:
Access to tuple elements is achieved using square brackets
[]:>>> t1[1] 2 >>> t1[0:2] (1, 2) >>> t1[-1] 'foo' >>> t1[::-1] ('foo', 2, 1)
Membership can be tested using
in:>>> 3 in t1 False >>> "foo" in t1 True
The number of elements can be obtained using
len:>>> len(t1) 3
This is very similar to what we have seen with strings, and we will soon see that it works the same for lists.
Tuple provide just two methods t.count(x), which returns the number of of times object x occurs in tuple t,
and t.index(x), which returns the index position of the left most occurrence of object x in tuple t:
>>> t1.count("bar")
0
>>> t1.count("foo")
1
>>> t1.index("foo")
2
If the object x is not found in t, count raises a ValueError:
>>> t1.index("bar")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: tuple.index(x): x not in tuple
5.1.1.3. Tuple immutability¶
As tuples are immutable, we cannot replace, delete or add any items after creation.
For instance, let’s try to replace the first element of t1:
>>> t1[0] = 3
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
If we try to extend the tuple with another one, a new tuple is created:
>>> id(t1)
140537354293504
>>> t1 += ("bar",)
>>> t1
(1, 2, 'foo', 'bar')
>>> id(t1)
140537354917632
This works similarly with strings, which are also immutable.
5.1.1.4. Named tuples¶
The standard library contains a collections module that provides various
collections-related functionalities. Among them is the
collections.namedtuple function that can create specialized tuples with an
extended syntax to access elements as object attributes.
Using such “named tuples” is a way to improve the readability of your program with a lightweight form of the object-oriented aspect of Python.
For instance, we might want to use tuples to represent structured information about restriction enzymes, each item of the tuple being one piece of information:
>>> ecor1 = ("EcoR1", "Ecoli restriction enzyme I", "gaatcc", 1, "sticky")
In order to coherently manipulate such tuples, we need to remember what position in the tuple corresponds to what piece of information.
With named tuples, we can create a special kind of tuple where each position is associated with a name:
>>> from collections import namedtuple
>>> RestrictEnzyme = namedtuple("RestrictEnzyme", ("name", "comment", "sequence", "cut", "end"))
We can now use this new type to represent a given restriction enzyme:
>>> ecor1 = RestrictEnzyme(name="EcoR1", comment="Ecoli restriction enzyme I", sequence="gaatcc", cut=1, end="sticky")
>>> ecor1
RestrictEnzyme(name='EcoR1', comment='Ecoli restriction enzyme I', sequence='gaatcc', cut=1, end='sticky')
It is also possible to omit the names when creating a named tuple, but one has to be careful to use the correct order for the items:
>>> ecor1 = RestrictEnzyme("EcoR1", "Ecoli restriction enzyme I", "gaatcc", 1, "sticky")
>>> ecor1
RestrictEnzyme(name='EcoR1', comment='Ecoli restriction enzyme I', sequence='gaatcc', cut=1, end='sticky')
Items inside a named tuple can be accessed by index, as with normal tuples, but also by name:
>>> ecor1[0]
'EcoR1'
>>> ecor1.name
'EcoR1'
>>> ecor1[2]
'gaatcc'
>>> ecor1.sequence
'gaatcc'
Accessing items by name makes it more explicit what the code is meant to do.
While we’re here, let’s create a whole collection of these interesting objects:
>>> bamh1 = RestrictEnzyme("BamH1", "type II restriction endonuclease from Bacillus amyloliquefaciens", "ggatcc", 1, "sticky")
>>> hind3 = RestrictEnzyme("HindIII", "type II site-specific nuclease from Haemophilus influenzae", "aagctt", 1 , "sticky")
>>> sma1 = RestrictEnzyme("SmaI", "Serratia marcescens", "cccggg", 3 , "blunt")
>>> digest = (ecor1, bamh1, hind3, sma1)
5.1.2. Lists¶
A list is a mutable ordered sequence of zero or more object references.
5.1.2.1. List creation¶
Lists can be created in similar ways as tuples, but using square brackets instead of parentheses.
An empty list is created using empty brackets:
>>> a = []
>>> type(a)
<class 'list'>
>>> print(a)
[]
Just calling the list type as a function also works:
>>> list()
[]
A difference with respect to tuple creation is that the comma is not required when creating a list with only one element:
>>> b = [1,]
>>> type(b)
<class 'list'>
>>> b = [1]
>>> type(b)
<class 'list'>
And brackets are not optional, since a sequence of comma separated items is otherwise a tuple:
>>> c = [1, 2]
>>> type(c)
<class 'list'>
>>> c = 1, 2
>>> type(c)
<class 'tuple'>
One can also create a list by converting another object,
using the list type as a conversion function:
>>> list("ESWN")
['E', 'S', 'W', 'N']
>>> list((1, 2, "foo"))
[1, 2, 'foo']
5.1.2.2. Lists as sequence types¶
The standard capabilities of sequence types work as for tuples and strings:
Access to list elements:
>>> l1 = [1, 2, "foo"] >>> l1[1] 2 >>> l1[0:2] [1, 2] >>> l1[-1] 'foo' >>> l1[::-1] ['foo', 2, 1]
Membership testing:
>>> 3 in l1 False >>> "foo" in l1 True
Number of elements:
>>> len(l1) 3
The count and index methods are also available:
>>> l1.count("bar")
0
>>> l1.count("foo")
1
>>> l1.index("foo")
2
>>> l1.index("bar")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 'bar' is not in list
5.1.2.3. Comparing lists¶
Lists can be compared using the standard comparison operators
(==, !=, >=, <=, <, >).
The comparison will be applied item by item
(and recursively for nested items such as lists in a list):
>>> one_two_three = [1, 2, 3]
>>> one_four = [1, 4]
>>> one_two_three > one_four
False
>>> one_two_threefour = [1, 2, [3, 4]]
>>> one_two_threefive = [1, 2, [3, 5]]
>>> one_two_threefive > one_two_threefour
True
5.1.2.4. List mutability¶
An important difference with tuples or strings is that one can replace, remove or add elements to a list.
Before proceeding, let’s look at our list’s identity:
>>> id(l1)
140537354412152
Now let’s try to replace it’s first element (at index 0):
>>> l1[0] = 3
>>> l1
[3, 2, 'foo']
>>> id(l1)
140537354412152
Our replacement attempt did not result in an exception, and the list identity has not changed: it is indeed the same object.
Now let’s extend the list with another one (concatenating):
>>> l1 += ["bar", "baz"]
>>> l1
[3, 2, 'foo', 'bar', 'baz']
>>> id(l1)
140537354412152
Contrary to what happened with our tuple, this did not result in the creation of a new object.
There is also an append method to add an element (just one) at the end of a list:
>>> l1.append("qux")
>>> l1
[3, 2, 'foo', 'bar', 'baz', 'qux']
>>> id(l1)
140537354412152
Again, identity was preserved.
A list modification equivalent to using += is achieved using the extend method:
>>> l1.extend([3.2, 17])
>>> l1
[3, 2, 'foo', 'bar', 'baz', 'qux', 3.2, 17]
To remove an element from a list, use the remove method:
>>> l1.remove(2)
>>> l1
[3, 'foo', 'bar', 'baz', 'qux', 3.2, 17]
If the element is present more than once, the first occurrence is removed:
>>> l1.append(3)
>>> l1
[3, 'foo', 'bar', 'baz', 'qux', 3.2, 17, 3]
>>> l1.remove(3)
>>> l1
['foo', 'bar', 'baz', 'qux', 3.2, 17, 3]
Another method that removes an element from a list is pop.
By default, it removes the last element of the list and returns it:
>>> l1.pop()
3
>>> l1.pop()
17
>>> l1
['foo', 'bar', 'baz', 'qux', 3.2]
It is possible to specify the index of the element to remove:
>>> l1.pop(2)
'baz'
>>> l1
['foo', 'bar', 'qux', 3.2]
>>> l1.pop(2)
'qux'
>>> l1
['foo', 'bar', 3.2]
If one tries to provide an index outside the range of existing positions in the list,
an IndexError exception is raised:
>>> l1.pop(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: pop index out of range
Yet another way to remove something from a list is with the del statement,
applied to one of the object reference contained in the list:
>>> del l1[1]
>>> l1
['foo', 3.2]
It can also be applied to a full slice of the list:
>>> del l1[0:2]
>>> l1
[]
It is also possible to assign a sequence of items to a list slice:
>>> l1[:] = [1, 2, "foo"]
>>> l1
[1, 2, 'foo']
>>> l1[1:] = [3, 3.2, 17]
>>> l1
[1, 3, 3.2, 17]
>>> l1[1:2] = [2, "foo"]
>>> l1
[1, 2, 'foo', 3.2, 17]
>>> l1[3:] = []
>>> l1
[1, 2, 'foo']
Finally, here are two very useful methods that can modify a list:
>>> numbers = [5, 1, 0, 3, 2, 4]
>>> numbers.reverse()
>>> numbers
[4, 2, 3, 0, 1, 5]
>>> numbers.sort()
>>> numbers
[0, 1, 2, 3, 4, 5]
It is also possible to sort a list in decreasing value order,
setting the reverse optional argument of sort to True:
>>> numbers.sort(reverse=True)
>>> numbers
[5, 4, 3, 2, 1, 0]
More generally, all operations available for sequence types and mutable sequence types are available for lists.
5.1.2.5. Copies of lists¶
A consequence of list mutability is that using the list type as a function
on a list argument results in a new object, not just a reference to the same
object:
>>> l2 = list(l1)
>>> print(l2)
[1, 2, 'foo']
>>> l1 is l2
False
This makes it possible to replace, remove or add items without affecting the original:
>>> l2[0] = 3
>>> l2
[3, 2, 'foo']
>>> l1
[1, 2, 'foo']
The same happens when using the copy method of a list:
>>> l3 = l1.copy()
>>> l1 is l3
False
>>> l3[1] = 4
>>> l3
[1, 4, 'foo']
>>> l1
[1, 2, 'foo']
However, the copy is only a shallow copy. This means that only the reference of the container is a copy, not the references of the contained items:
>>> l1[0] is l3[0]
True
The reference of the items that were replaced have changed, though:
>>> l1[1] is l3[1]
False
Warning
When working with copies of objects containing references to mutable objects, be aware that the modification of a contained object accessed through a copy of the original container also affects the object contained in the original, since it is actually the same:
>>> l1 = [[1, 2], [3, 4]]
>>> l2 = l1.copy()
>>> l2[0].append("foo")
>>> l2
[[1, 2, 'foo'], [3, 4]]
>>> l1
[[1, 2, 'foo'], [3, 4]]
5.1.2.6. Lists Comprehensions¶
Small lists are often created using literals but long lists are usually created programmatically. To create a list from another sequence object, Python offers a very convenient syntax: the list comprehension. A list comprehension is an expression where a loop, with an optional condition, is enclosed in square brackets. The loop is used to generate items for the list and the condition filters out unwanted items.
Here are two nice examples where we use list comprehensions to build lists of restriction enzyme names from our tuple of restriction enzyme named tuples:
>>> [enz.name for enz in digest]
['EcoR1', 'BamH1', 'HindIII', 'SmaI']
>>> [enz.name for enz in digest if enz.end != "blunt"]
['EcoR1', 'BamH1', 'HindIII']
5.1.3. List or tuple, which one should I choose?¶
We have seen that lists and tuples behave similarly in many aspects. The main reason to choose one or the other relates to mutability:
Use a list if you need to modify the data.
Use a tuple if you want read-only data, or simply if you know that you will not need to modify the data.
In the second case, this may protect you against programming errors, and you may benefit from better performance.
5.2. Set Types¶
Set types are unordered collections data types containing unique elements.
They are mainly interesting due to their fast membership testing,
and classical mathematical operations like union, intersection, difference.
They are also used to easily eliminate duplicates from a collection.
As collections,
they support the in and len operators and are iterable.
However, contrary to sequence types, they are not ordered.
Consequently, they do not support item access by index or slicing. When
iterated, set types provide their items in an arbitrary order.
Two builtin set types are available:
set, which is mutable, and frozenset, which is not.
Only hashable objects may be part of a set (or frozenset).
Hashable objects are objects for which it is possible to compute a “hash” value
(a value summarizing the object, provided by their __hash__ method), that
is always the same throughout the object’s lifetime, and which can be compared
for equality. This enables fast membership testing and elimination of
duplicates.
The built-in immutable data types, such as float, frozenset,
int, str, and tuple, are hashable and can be part of a (frozen)set.
An exception is tuples that contain non hashable elements.
The built-in mutable data types, such as dict, list, and set,
are not hashable, so they cannot part of a (frozen)set.
5.2.1. Sets¶
A set is an unordered collection of zero or more object references that refer to
hashable objects. Sets are mutable, so we can easily add or remove items, but
since they are unordered they have no notion of index position and so cannot
be sliced or strided.
5.2.1.1. Set creation¶
An empty set can be created calling the set data type as a function, with no argument:
>>> s0 = set()
>>> type(s0)
<class 'set'>
>>> print(s0)
set()
A set with one or more elements can be created by enclosing the elements between curly braces {}:
>>> s1 = {"foo"}
>>> s1
{'foo'}
>>> s2 = {"baz", "qux"}
>>> s2
{'qux', 'baz'}
>>> s3 = {"foo", "bar", "baz"}
>>> s3
{'foo', 'baz', 'bar'}
Note
Empty curly braces create an empty dict, not an empty set.
It is also possible to create a set calling the set type as a function on
an iterable of hashable elements:
>>> nucleotides = set("ACGTU")
>>> nucleotides
{'U', 'A', 'G', 'T', 'C'}
Here, the individual letters of the string have been used as elements in the set.
>>> unique_numbers = set([4, 2, 1, 2, 5, 1, 9, 3, 2, 1]) >>> unique_numbers
{1, 2, 3, 4, 5, 9}
Note how duplicates are eliminated in a set.
Since sets are not hashable, it is not possible to have a set inside a set.
However, the frozenset type is a mutable set type, which is hashable.
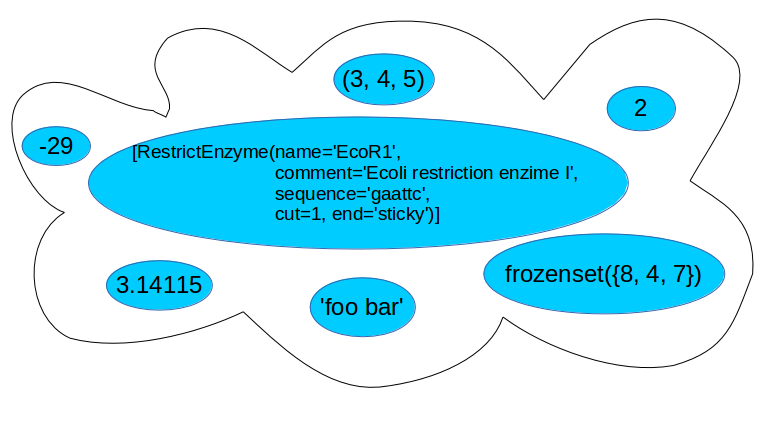
This figure illustrates the set created by the following code snippet:
>>> miscellanea = {"foo bar", 2, ecor1, frozenset({8, 4, 7}), -29, (3, 4, 5)}
Sets always contains unique items. It safe to add several times the same item but pointless.
5.2.1.2. Operations on sets¶
Sets support len and fast membership testing in and not in:
>>> len(s1)
1
>>> len(s2)
2
>>> len(s3)
3
>>> "foo" in s1
True
>>> "foo" in s2
False
>>> "qux" not in s1
True
>>> "qux" not in s2
False
They also support usual set operators:
Union:
|Intersection:
&Difference:
-Symmetric difference:
^
Here are some examples:
>>> pecan = set("pecan")
>>> pie = set("pie")
>>> print(pecan, "...", pie)
{'n', 'p', 'c', 'a', 'e'} ... {'p', 'i', 'e'}
>>> pecan | pie
{'n', 'p', 'a', 'i', 'e', 'c'}
>>> pecan & pie
{'p', 'e'}
>>> pecan - pie
{'n', 'a', 'c'}
>>> pie - pecan
{'i'}
>>> pecan ^ pie
{'n', 'c', 'a', 'i'}
>>> pie ^ pecan
{'n', 'a', 'i', 'c'}
Sets can be compared using standard comparison operators, and the isdisjoint method.
Sets are equal if they contain the same elements:
>>> set("baobab") == {"a", "b", "o"}
True
>>> set("baobab") == set("blackout")
False
s1 ^ s2 != s1 | s2
False
Sets are disjoint if they do not share any element:
>>> s1.isdisjoint(s2)
True
Inequalities test inclusion relationships between sets:
>>> set("baobab") < set("blackout")
True
>>> {1, 2, 3} < {1, 2, 4}
False
>>> {1, 2, 3} >= {1, 2, 4}
False
>>> {1, 2, 3} < {1, 2, 3, 4}
True
>>> {1, 2, 3} <= {1, 2, 3, 4}
True
Since they are mutable, sets also support methods and operators that modify them.
The add method adds an element to a set:
>>> nucleotides
{'U', 'A', 'G', 'T', 'C'}
>>> id(nucleotides)
140537313773528
>>> nucleotides.add("N")
>>> nucleotides
{'U', 'A', 'G', 'T', 'C', 'N'}
>>> id(nucleotides)
140537313773528
The update method adds the elements in the iterable given as argument:
>>> nucleotides.update(set("WSMKRY"))
>>> nucleotides
{'K', 'W', 'U', 'A', 'S', 'G', 'R', 'M', 'T', 'C', 'Y', 'N'}
An element can be removed from a set using the remove method:
>>> nucleotides.remove("U")
>>> nucleotides
{'K', 'W', 'A', 'S', 'G', 'R', 'M', 'T', 'C', 'Y', 'N'}
It is also possible to use updating versions of the standard set operations:
>>> nucleotides &= set("ACGT")
>>> nucleotides
{'C', 'T', 'G', 'A'}
>>> id(nucleotides)
140537313773528
>>> nucleotides |= set("RY")
>>> nucleotides
{'T', 'A', 'C', 'Y', 'G', 'R'}
>>> nucleotides -= set("YTC")
>>> nucleotides
{'A', 'G', 'R'}
More details about available methods and operators can be found here: https://docs.python.org/3/library/stdtypes.html#set-types-set-frozenset
5.2.1.3. Set Comprehension¶
As we can build a list using an expression (see Lists Comprehensions) we can create sets
>>> {enz.name for enz in digest}
{'HindIII', 'SmaI', 'BamH1', 'EcoR1'}
>>> {enz.name for enz in digest if enz.end != 'blunt'}
{'HindIII', 'BamH1', 'EcoR1'}
5.2.2. Frozensets¶
Frozensets behave pretty much like sets, except that they are immutable.
As already mentioned, one implication is that frozensets are hashable, and can therefore be elements of a set or a frozenset.
The other main implication is that, obviously, operations that modify sets are not valid for frozensets.
Frozensets have to be created via a call to frozenset.
With no argument, an empty frozenset is returned:
>>> f0 = frozenset()
>>> type(f0)
<class 'frozenset'>
>>> print(f0)
frozenset()
With an iterable as argument, a frozenset is made from the elements in the iterable:
>>> f1 = frozenset(["foo"])
>>> f2 = frozenset(s2)
>>> f3 = frozenset(("bar", "foo", "baz"))
>>> f1
frozenset({'foo'})
>>> f2
frozenset({'qux', 'baz'})
>>> f3
frozenset({'foo', 'baz', 'bar'})
Then, frozensets can be manipulated using the same operations as sets, provided that they do not modify them:
>>> f1 | f2
frozenset({'qux', 'foo', 'baz'})
>>> f2 & f3
frozenset({'baz'})
>>> "foo" in f2
False
>>> f1.isdisjoint(f3)
False
The updating versions of the operators will create a new object:
>>> id(f3)
140537313774392
>>> f3 ^= f2
>>> f3
frozenset({'qux', 'foo', 'bar'})
>>> id(f3)
140537313773960
Attempts to use modifying set methods result in AttributeError exceptions:
>>> f1.add("baz")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'frozenset' object has no attribute 'add'
>>> f2.update({"bar", "foo"})
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'frozenset' object has no attribute 'update'
5.3. Mapping Types¶
Mappings are collections of (key, value) items and provide methods for accessing items, keys, and values.
In a mapping type, a value is associated to a key. The key provides a direct access to the corresponding value, without iterating over all the collection.
In Python the mapping types are also called “dictionaries”.
Only hashable objects may be used as dictionary keys, so immutable data types
such as float, frozenset, int, str, and tuple can be used as dictionary keys (except tuples containing non hashable items), but
mutable types such as dict, list, and set cannot.
On the other hand, each value
associated to a key can be an object reference referring to an object of any type,
including numbers, strings, lists, sets, dictionaries, functions, and so on.
Dictionaries can be compared using the standard equality comparison
operators (== and !=), with the comparisons being applied item by item (and
recursively for nested items such as tuples or dictionaries inside dictionaries).
Comparisons using the other comparison operators (<, <=, >=, >)
are not supported since they don’t make sense for unordered collections such as dictionaries.
dict type.collections module of the standard library provides a handy collections.defaultdict type.5.3.1. Dictionaries¶
A dict is an unordered collection of zero or more (key, value) pairs whose keys are object references that refer to hashable objects, and whose values are object references referring to objects of any type. Dictionaries are mutable, so we can easily add or remove items, but since they are unordered they have no notion of index position and so cannot be sliced or strided.
5.3.1.1. Dict creation¶
As you may guess from previous collection examples, an empty dict can be
created using the dict data type called as a function, with no arguments:
>>> d0 = dict()
>>> type(d0)
<class 'dict'>
>>> print(d0)
We already mentioned that an empty pair of curly braces created an empty dict.
Curly braces can also be used to create a non empty dict, with items consisting
in key: value pairs separated by commas:
>>> d = {"id": 1948, "name": "Washer", "size": 3}
>>> d
{'id': 1948, 'name': 'Washer', 'size': 3}
Or the dict type can be used to convert a sequence of (key, value)
tuples into a dict:
>>> d = dict([("id", 1948), ("name", "Washer"), ("size", 3)])
>>> d
{'id': 1948, 'name': 'Washer', 'size': 3}
The dict type also accepts keyword arguments that will result in (key,
value) items in the returned dict:
>>> d = dict(id=1948, name="Washer", size=3)
>>> d
{'id': 1948, 'name': 'Washer', 'size': 3}
Another way of creating dictionaries is to use a dictionary comprehension, a topic we will cover later.

The above figure illustrates the dictionary created by the following code snippet:
>>> d1 = {0: 1 , (2, 10): "foo", -1: ["a", "b", "c"], "Ecor1": ecor1}
5.3.1.2. Operations on dicts¶
Brackets are used to access individual values:
>>> d1[0]
1
>>> d1[-1]
['a', 'b', 'c']
If the key is not present in the dict, a KeyError exception is raised:
>>> d1[91]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 91
Brackets can also be used to add, replace or delete dictionary items.
To add a new item, use the = operator:
>>> d1["X"] = 59
>>> d1
{0: 1, (2, 10): 'foo', -1: ['a', 'b', 'c'], 'Ecor1': {'name': 'EcoR1', 'seq': 'gaattc', 'comment': 'restriction site 1 for Ecoli'}, 'X': 59}
Dictionary keys are unique, so if we add a (key, value) item whose key is the same as an existing key, the effect is to replace the value associated to that key with the new one:
>>> d1[(2, 10)] = "bar"
>>> d1
{0: 1, (2, 10): 'bar', -1: ['a', 'b', 'c'], 'Ecor1': {'name': 'EcoR1', 'seq': 'gaattc', 'comment': 'restriction site 1 for Ecoli'}, 'X': 59}
To delete an item use the del statement:
>>> del d1["Ecor1"]
>>> d1
{0: 1, (2, 10): 'bar', -1: ['a', 'b', 'c'], 'X': 59}
A KeyError Exception Handling is raised if no item has that key:
>>> del d1[frozenset({1, 2, 3})]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: frozenset({1, 2, 3})
Items can also be removed (and returned) from the dictionary using the
dict.pop method, one of the various methods provided by the dict type:
Syntax Description |
|
|---|---|
d.clear() |
Removes all items from dict d |
d.copy() |
Returns a shallow copy of dict d |
d.fromkeys(s, v) |
Returns a dict whose keys are the items in sequence s and whose values are None or v if v is given |
d.get(k) |
Returns key k’s associated value, or None if k isn’t in dict d |
d.get(k, v) |
Returns key k’s associated value, or v if k isn’t in dict d |
d.items() |
Returns a view of all the (key, value) pairs in dict d |
d.keys() |
Returns a view of all the keys in dict d |
d.pop(k) |
Returns key k’s associated value and removes the item whose key is k, or raises a KeyError exception if k isn’t in d whose key is k, or returns v if k isn’t in dict d |
d.popitem() |
Returns and removes an arbitrary (key, value) pair from dict d, or raises a KeyError exception if d is empty |
d.setdefault(k, v) |
The same as the dict.get() method, except that if the key is not in dict d, a new item is inserted with the key k , and with a value of None or of v if v is given |
d.update(a) |
Adds every (key, value) pair from a that isn’t in dict d to d , and for every key that is in both d and a, replaces the corre- sponding value in d with the one in a — a can be a dictionary, an iterable of (key, value) pairs, or keyword arguments |
Note
In Python 3, the dict.items, dict.keys, and dict.values methods all return “dictionary
views”. A dictionary view is effectively a read-only iterable object that appears
to hold the dictionary items or keys or values, depending on the view we have
asked for. In general, we can simply treat views as iterables. However, two things make
a view different from a normal iterable. One is that if the dictionary the view
refers to is changed, the view reflects the change. The other is that key and
item views support some set-like operations. Given dictionary view v and set
or dictionary view x, the supported operations are:
Intersection:
v & xUnion:
v | xDifference:
v - xSymmetric difference:
v ^ x
In Python3
>>> d = {1: "a", 2: "b", 3: "c", 4: "e"}
>>> v = d.keys()
>>> v
dict_keys([1, 2, 3, 4])
>>> type(v)
<class 'dict_keys'>
>>> d[5] = "c"
>>> v
dict_keys([1, 2, 3, 4, 5])
>>> x = {4, 5, 6}
>>> v & x
{4, 5}
>>> v - x
{1, 2, 3}
>>> v | x
{1, 2, 3, 4, 5, 6}
>>> v ^ x
{1, 2, 3, 6}
5.3.1.3. Dict Comprehension¶
A dictionary comprehension is an expression and a loop with an optional condition enclosed in braces, very similar to a set comprehension. Like list and set comprehensions, two syntaxes are supported:
{keyexpression: valueexpression for key, value in iterable}
{keyexpression: valueexpression for key, value in iterable if condition}
ecor1 = ("EcoR1", "Ecoli restriction enzime I", "gaattc", 1, "sticky")
bamh1 = ("BamH1", "type II restriction endonuclease from Bacillus amyloliquefaciens", "ggatcc", 1, "sticky")
hind3 = ("HindIII", "type II site-specific nuclease from Haemophilus influenzae", "aagctt", 1 , "sticky")
sma1 = ("SmaI", "Serratia marcescens", "cccggg", 3 , "blunt")
digest = [ecor1, bamh1, hind3, sma1]
# now I need a collection to acces direcly to the enzyme given its name
# so I will create a dictionary where keys are enzyme name and values the enzymes
frig = {enz[0] : enz for enz in digest}
# if I want a collection with only cohesive end enzymes
cohesive_enz = {enz[0]] : enz for enz in digest if enz[-1] != 'blunt'}
5.4. Iterating and copying collections¶
Once we have collections of data items, it is natural to want to iterate over all the items they contain. Another common requirement is to copy a collection. There are some subtleties involved here because of Python’s use of object references (for the sake of efficiency), so in the last subsection, we will examine how to copy collections and get the behavior we want.
5.4.1. Iterating over collections¶
An iterable data type is one that can return each of its items one at a time.
5.4.1.1. iterator¶
An iterator is an object which is able read through a collection and return items one by one in turn.
The next method of iterator returns each successive item in turn, and raises a StopIteration
exception when there are no more items.
The order in which items are returned depends on the underlying iterable. In the case of lists and tuples, items are normally returned in sequential order starting from the first item (index position 0), but some iterators return the items in an arbitrary order for example, dictionary and set iterators.
Any (finite) iterable, i , can be converted into a tuple by calling tuple(i) , or can be converted into a list by calling list(i) .
Iterator support also all(), any(), len(), min(), max(), and sum() functions.
Here are a couple of usage examples:
>>> x = [-2, 9, 7, -4, 3]
>>> all(x), any(x), len(x), min(x), max(x), sum(x)
(True, True, 5, -4, 9, 13)
>>> x.append(0)
>>> all(x), any(x), len(x), min(x), max(x), sum(x)
(False, True, 6, -4, 9, 13)
The enumerate() function takes an iterator and returns an enumerator object. This object can be treated like an iterator, and at each iteration it returns a 2-tuple with the tuple’s first item the iteration number (by default starting from 0)
seq = 'TACCTTCTGAGGCGGAAAGA'
for i , b in enumerate(seq):
print(i, b)
0 T
1 A
2 C
3 C
4 T
5 T
6 C
... on so on
140
Common Iterable Operators and Functions
Syntax |
Description |
|---|---|
s + t |
Returns a sequence that is the concatenation of sequences s and t |
s * n |
Returns a sequence that is int n concatenations of sequence s and t |
x in i |
Returns True if item x is in iterable i ; use not in to reverse the test |
all(i) |
Returns True if every item in iterable i evaluates to True |
any(i) |
Returns True if any item in iterable i evaluates to True |
enumerate(i, start) |
Normally used in for … in loops to provide a sequence of (index, item) tuples with indexes starting at 0 or start ; |
len(x) |
Returns the “length” of x . If x is a collection it is the number of items; if x is a string it is the number of characters. |
max(i, key) |
Returns the biggest item in iterable i or the item with the biggest key(item) value if a key function is given |
min(i, key) |
Returns the smallest item in iterable i or the item with the smallest key(item) value if a key function is given |
range(start, stop, step) |
Returns an integer iterator. With one argument ( stop ), the iterator goes from 0 to stop - 1; with two arguments ( start , stop ) the iterator goes from start to stop - 1; with three arguments it goes from start to stop - 1 in steps of step . |
reversed(i) |
Returns an iterator that returns the items from iterator i in reverse order |
sorted(i, key, reverse) |
Returns a list of the items from iterator i in sorted order; key is used to provide DSU (Decorate, Sort, Undecorate) sorting. If reverse is True the sorting is done in reverse order. |
sum(i, start) |
Returns the sum of the items in iterable i plus start (which defaults to 0); i may not contain strings |
zip(i1, …, iN) |
Returns an iterator of tuples using the iterators i1 to iN ; see text |
5.4.1.2. The for … in Statement¶
Python’s for loop has the following syntax:
- for variable in iterable:
do something
- else:
do something else
the else block is optional.
Note
We already specify that Python uses indentation to signify its block structure. So here the identation is very important. The block “for” begin with the for … in statement and included all lines which are right indented. The block ends when the code is align again with the for … in statement for instance:
1for i in [1,2,3]:
2 begin of **for** block of code
3 do something
4 do another thing
5print("foo")
The Python style guidelines (pep 8) recommend four spaces per level of indentation, and only spaces (no tabs).
In for … in loop, the variable is set to refer to each object in the iterable in turn. each line of code in the for .. in block is executed at each turn using the variable refering the new object.
bases = 'acgt'
for b in bases:
print('base =', b)
base = a
base = c
base = g
base = t
z = 0
for i in [1,2,3]:
z += i
print(f"i = {i}, z = {z}")
i = 1, z = 1
i = 2, z = 3
i = 3, z = 5
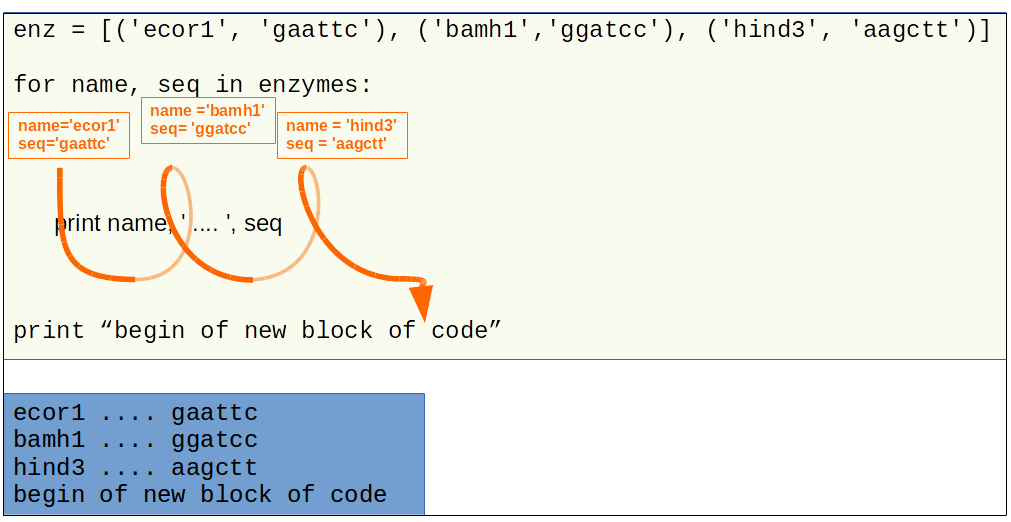
the schema above symbolizes the code execution flow with the “for” loop.¶
in green the source code
in blue the execution source code results
in orange the execution flow
The for loops has an optional else clause. This latter is rather confusingly named since the else clause’s suite is always executed if the loop terminates normally. If the loop is broken out of due to a break statement, or a return statement (if the loop is in a function or method), or if an exception is raised, the else clause’s suite is not executed.
Note
The variable is normally often a single variable but may be a sequence of variables, usually in the form of a tuple. If a tuple or list is used for the variable, each item is unpacked into the matchin items of the variable:
enzymes = [('ecor1', 'gaattc'), ('bamh1','ggatcc'), ('hind3', 'aagctt')]
for name, seq in enzymes:
print(name, ' .... ', seq)
ecor1 .... gaattc
bamh1 .... ggatcc
hind3 .... aagctt
5.4.1.2.1. break and continue¶
If a continue statement is executed inside the for … in loop’s suite, control is
immediately passed to the top of the loop and the next iteration begins. If the
loop runs to completion it terminates, and any else suite is executed. If the
loop is broken out of due to a break statement, or a return statement (if the loop
is in a function), or if an exception is raised, the else clause’s suite
is not executed. (If an exception occurs, Python skips the else clause and looks
for a suitable exception handler—this is covered in the next section.)
enzymes = [('ecor1', 'gaattc'), ('bamh1','ggatcc'), ('hind3', 'aagctt')]
for name, seq in enzymes:
if name == 'bamh1':
continue
print(name, ' .... ', seq)
ecor1 .... gaattc
hind3 .... aagctt

the schema above symbolizes the code execution flow with the “for” loop, with a continue statement.¶
in green the source code
in blue the execution source code results
in orange the execution flow
enzymes = [('ecor1', 'gaattc'), ('bamh1','ggatcc'), ('hind3', 'aagctt')]
for name, seq in enzymes:
if name == 'bamh1':
break
print(name, ' .... ', seq)
ecor1 .... gaattc
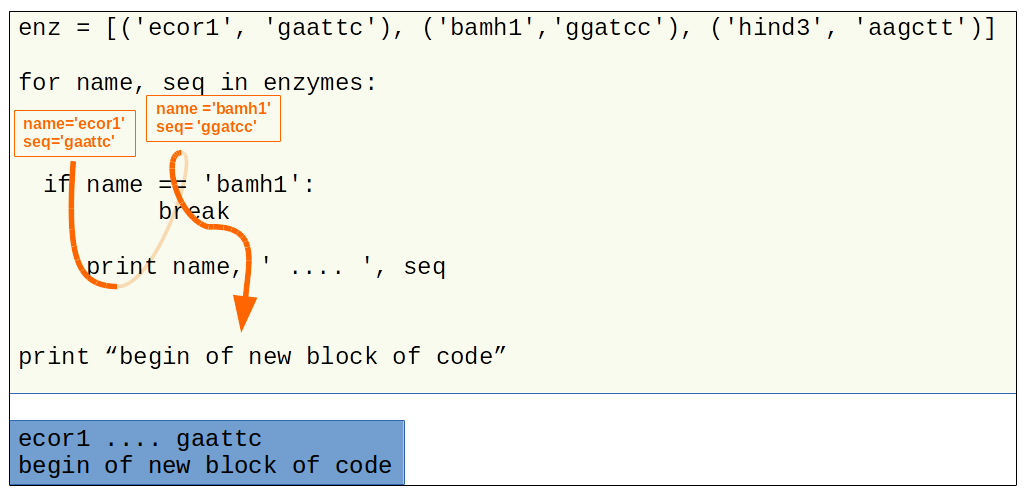
the schema above symbolizes the code execution flow with the “for” loop, with a break statement.¶
in green the source code
in blue the execution source code results
in orange the execution flow
5.4.2. copying collections¶
Since Python uses object references, when we use the assignment operator ( = ), no copying takes place. If the right-hand operand is a literal such as a string or a number, the left-hand operand is set to be an object reference that refers to the in-memory object that holds the literal’s value. If the right-hand operand is an object reference, the left-hand operand is set to be an object reference that refers to the same object as the right-hand operand. One consequence of this is that assignment is very efficient.
In some situations, we really do want a separate copy of the collection (or other mutable object). For sequences, when we take a slice. The slice is always an independent copy of the items copied. So to copy an entire sequence we can do this:
>>> ascii = ['a','b','c']
>>> ascii_copy = ascii[:]
For dictionaries and sets, copying can be achieved using dict.copy() and set.copy() . In addition, the copy module provides the copy.copy() function that returns a copy of the object it is given. Another way to copy the built-in collec- tion types is to use the type as a function with the collection to be copied as its argument. Here are some examples:
copy_of_dict_d = dict(d)
copy_of_list_L = list(L)
copy_of_set_s = set(s)
Note, though, that all of these copying techniques are shallow that is, only object references are copied and not the objects themselves.
>>> ascii = ['a','b','c']
>>> ascii_copy = ascii[:] # shallow copy
>>> ascii[2] = 'z'
>>> ascii
['a', 'b', 'z']
>>> ascii_copy = ['a','b','c']
>>> ascii_copy.append('e')
>>> ascii_copy
['a','b','c','e']
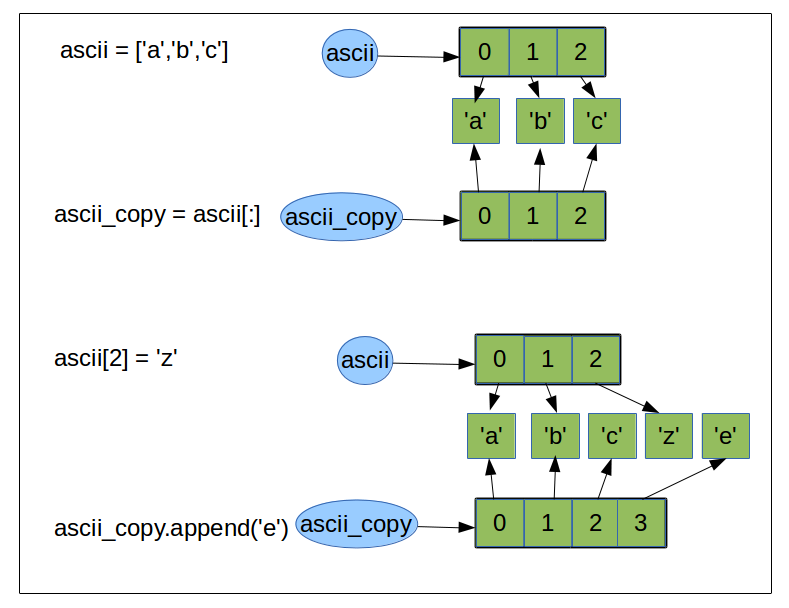
the schema above represent what python do behind the scene when we do a shallow copy. Only object references are copied and not the objects themselves.¶
For immutable data types like numbers and strings this has the same effect as copying (except that it is more efficient). But for mutable data types such as nested collections this means that the objects they refer to are referred to both by the original collection and by the copied collection (the objects in l and l2 have the same id()).
>>> ascii = ['a','b','c']
>>> integer = [1,2,3]
>>> l = [ascii, integer]
>>> l2 = l[:] # shallow copy
>>>
>>> l[0]
['a', 'b', 'c']
>>> print id(l), id(l2)
140530764842408 140530764842480 # l and l2 are 2 different objects
>>> id(ascii)
140504986917992
>>> id(l[0])
140504986917992
>>> id(l2[0])
140504986917992
# the object they refer are the same

the schema above represent what python do behind the scene when we do a shallow copy.¶
>>> ascii[0] = 'z'
>>> l[0]
['z', 'b', 'c']
>>> l2[0]
['z', 'b', 'c']
>>> l2.append('foo')
>>> l2
[['z', 'b', 'c'],[1, 2, 3], 'foo']
>>> l
[['z', 'b', 'c'],[1, 2, 3]]
>>> tpl = (ascii, integer)
>>> tpl
(['z', 'b', 'c'], [1, 2, 3])
>>> integer[0] = -99
>>> tpl
(['z', 'b', 'c'], [-99, 2, 3])
In these conditions we must keep in mind that if we mutate an item of the collection the both collections are modified. In programmation, we call this a side effect. We saw the side effect problem on list and tuple example but it’s also true with dictionnaries.
If we really need independent copies of arbitrarily nested collections, we have to do a deep-copy.
>>> import copy
>>> ascii = ['a','b','c']
>>> integer = [1,2,3]
>>> l = [ascii, integer]
>>> l2 = copy.deepcopy(l)
140481236949328 140481236947168 # l and l2 are 2 different objects
>>> print id(l[0]), id(l2[0])
139909363381672 139909362940312 # the objects they refer have the same value but are distincts.
>>> ascii[0] = 'z'
>>> l
[['z', 'b', 'c'], [1, 2, 3]]
>>> l2
[['a', 'b', 'c'], [1, 2, 3]]
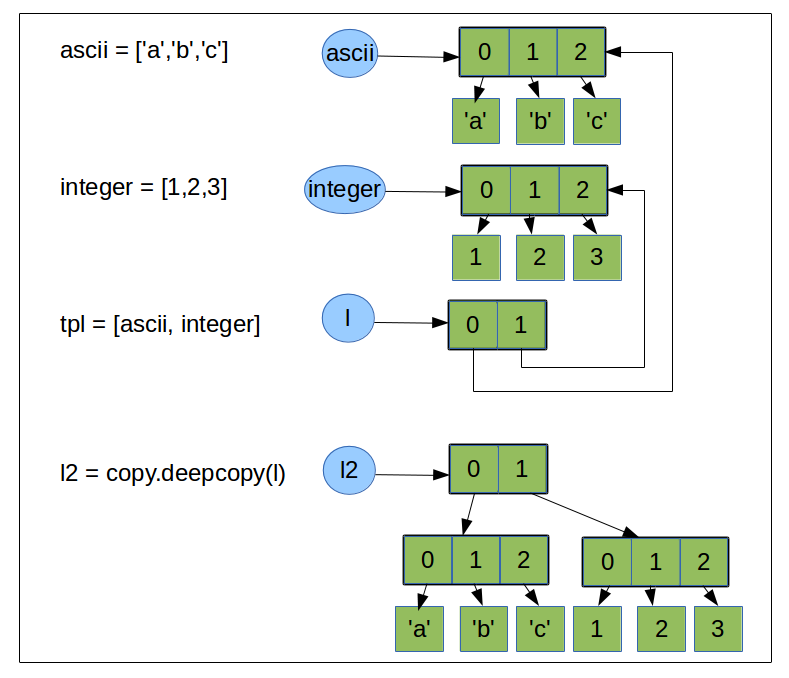
The above schema represents what Python does behind the scene when we do a deep copy.¶
Usually the terms copy and shallow copy are used interchangeably. For deep copy we have to mention it explicitly.
5.5. Exercises¶
5.5.1. Exercise¶
Draw the representation in memory and specify the data type of each object of the following expressions:
x = [1, 2, 3, 4]
y = x[1]
y = 3.14
x[1] = 'foo'
and
x = [1, 2, 3, 4]
x += [5, 6]
Compare
x = 3
y = x
y += 3
x = ?
y = ?
and
x = [1,2]
y = x
y += [3,4]
x = ?
y = ?
5.5.2. Exercise¶
Note
sum is a function that returns the sum of all the elements of a list.
Without using the Python shell, tell what are the effects of the following statements:
x = [1, 2, 3, 4]
x[3] = -4 # What is the value of x now?
y = sum(x) / len(x) # What is the value of y? Why?
5.5.3. Exercise¶
Draw the representation in memory of the x and y variables when the following code is executed:
x = [1, ['a', 'b', 'c'], 3, 4]
y = x[1]
y[2] = 'z'
# What is the value of x?
5.5.4. Exercise¶
From the list l = [1, 2, 3, 4, 5, 6, 7, 8, 9] generate 2 lists:
l1containing all odd valuesl2all even values.
5.5.5. Exercise¶
Note
A codon is a triplet of nucleotides. A nucleotide can be one of the four letters A, C, G, T
Write a function that returns a list containing strings representing all possible codons.
Write the pseudocode before proposing an implementation.
5.5.6. Exercise¶
Write a function uniqify which takes a list as parameter and returns a new list
without any duplicate, regardless of the order of the items.
For instance:
>>> l = [5, 2, 3, 2, 2, 3, 5, 1]
>>> uniqify(l)
[1,2,3,5] # is one of the valid solutions
5.5.7. Exercise¶
Note
A k-mer is a word made of k letters.
We need to compute the occurrence of all k-mers of a given length present in a sequence.
Below we propose 2 algorithms.
5.5.7.1. pseudo code 1¶
5.5.7.2. pseudo code 2¶
Compare the pseudocode of these 2 algorithms and implement the fastest one.:
"""gtcagaccttcctcctcagaagctcacagaaaaacacgctttctgaaagattccacactcaatgccaaaatataccacag
gaaaattttgcaaggctcacggatttccagtgcaccactggctaaccaagtaggagcacctcttctactgccatgaaagg
aaaccttcaaaccctaccactgagccattaactaccatcctgtttaagatctgaaaaacatgaagactgtattgctcctg
atttgtcttctaggatctgctttcaccactccaaccgatccattgaactaccaatttggggcccatggacagaaaactgc
agagaagcataaatatactcattctgaaatgccagaggaagagaacacagggtttgtaaacaaaggtgatgtgctgtctg
gccacaggaccataaaagcagaggtaccggtactggatacacagaaggatgagccctgggcttccagaagacaaggacaa
ggtgatggtgagcatcaaacaaaaaacagcctgaggagcattaacttccttactctgcacagtaatccagggttggcttc
tgataaccaggaaagcaactctggcagcagcagggaacagcacagctctgagcaccaccagcccaggaggcacaggaaac
acggcaacatggctggccagtgggctctgagaggagaaagtccagtggatgctcttggtctggttcgtgagcgcaacaca"""
Compute the 6-mers occurrences of the sequence above, and print each 6-mer and it’s occurrence one per line.
5.5.7.3. Bonus¶
Print the k-mers by ordered by occurrences.
5.5.8. Exercise¶
Test data:
seq = 'acggcaacatggctggccagtgggctctgagaggagaaagtccagtggatgctcttggtctggttcgtgagcgcaacaca'
5.5.9. Exercise¶
Build the following enzymes collection:
ecor1 = ("EcoRI", "Ecoli restriction enzime I", "gaattc", 1, "sticky")
ecor5 = ("EcoRV", "Ecoli restriction enzime V", "gatatc", 3, "blunt")
bamh1 = ("BamHI", "type II restriction endonuclease from Bacillus amyloliquefaciens ", "ggatcc", 1, "sticky")
hind3 = ("HindIII", "type II site-specific nuclease from Haemophilus influenzae", "aagctt", 1, "sticky")
taq1 = ("TaqI", "Thermus aquaticus", "tcga", 1, "sticky")
not1 = ("NotI", "Nocardia otitidis", "gcggccgc", 2, "sticky")
sau3a1 = ("Sau3aI", "Staphylococcus aureus", "gatc", 0, "sticky")
hae3 = ("HaeIII", "Haemophilus aegyptius", "ggcc", 2, "blunt")
sma1 = ("SmaI", "Serratia marcescens", "cccggg", 3, "blunt")
We have two DNA fragments:
dna_1 = """tcgcgcaacgtcgcctacatctcaagattcagcgccgagatccccgggggttgagcgatccccgtcagttggcgtgaattcag
cagcagcgcaccccgggcgtagaattccagttgcagataatagctgatttagttaacttggatcacagaagcttccaga
ccaccgtatggatcccaacgcactgttacggatccaattcgtacgtttggggtgatttgattcccgctgcctgccagg"""
dna_2 = """gagcatgagcggaattctgcatagcgcaagaatgcggccgcttagagcgatgctgccctaaactctatgcagcgggcgtgagg
attcagtggcttcagaattcctcccgggagaagctgaatagtgaaacgattgaggtgttgtggtgaaccgagtaag
agcagcttaaatcggagagaattccatttactggccagggtaagagttttggtaaatatatagtgatatctggcttg"""
Which enzymes cut:
dna_1?dna_2?dna_1but notdna_2?In a file
Copy paste the enzymes above
Write a function seq_one_line which takes a multi lines sequence and returns a sequence in one line.
Write a function enz_filter which takes a sequence and a list of enzymes and returns a new list containing the enzymes which have a restriction site in the sequence.
Use the above functions to compute the enzymes which cut
dna_1, apply the same functions to compute the enzymes which cutdna_2and compute the difference between the enzymes which cutdna_1and those which cutdna_2.
5.5.10. Exercise¶
Given the following dict:
d = {1 : 'a', 2 : 'b', 3 : 'c' , 4 : 'd'}
We want obtain a new dict with the keys and the values inverted so we will obtain:
>>> inverted_d
{'a': 1, 'c': 3, 'b': 2, 'd': 4}
5.5.11. Bonus¶
Can you explain what’s happening here?
>>> x = []
>>> x.append(x.append)
>>> x[0](len)
>>> x[1](x)
2
>>> x[0](x.pop)
>>> x[1](x)
3
>>> x[0](x[2]())
>>> x[1](x)
3
>>> x[2](1)(x)
2
>>> y = x[1](0)
>>> y(y)