4. Data Types¶
It is now time to have a more detailed look at the basic data types we can work with in Python.
4.1. NoneType¶
The sole value of the type NoneType is None.
The None value represents something which is unknown, undefined.
None is also frequently used to represent the absence of a value, as when default arguments are not passed to a function.
>>> print(type(None))
<class 'NoneType'>
>>> a = None
>>> b = None
>>> id(a)
140615784725232
>>> id(b)
140615784725232
Note
the id function returns an integer representing its “identity” (currently implemented as its address in memory).
Therefore, if two objects have the same id they are actually the same object.
When converted into a Boolean (see below), the None value is converted into False:
>>> bool(None)
False
4.2. Boolean¶
These represent the truth values False and True.
The two objects representing the values False and True are the only Boolean objects.
The Boolean type is a subtype of plain integers, and Boolean values behave like the values 0 and 1,
respectively, in almost all contexts, the exception being that when converted to a string,
the strings "False" or "True" are returned, respectively.
4.3. Numeric types¶
The two main built-in numeric types are integers and floating point numbers.
4.3.1. Integers¶
The size of an integer is limited only by the machine’s memory. It is therefore perfectly possible to create and work with integers hundred digits long. However, they will be slower to use than integers that can be represented natively by the machine processor.
Integer literals are written in base 10 by default but other bases can be used:
>>> 126 # decimal
126
>>> 0b1111110 # binary (with a leading 0b)
126
>>> 0o176 # octal (with a leading 0o)
126
>>> 0x7e # hexadecimal (with a leading 0x)
126
4.3.2. Floats¶
The type float holds double precision floating point numbers whose range depends on the native C compiler Python was built with.
They have a relative precision and cannot be reliably compared for equality. Numbers of type float are written with a decimal point
or exponantial notation:
>>> -2e9
-2000000000.0
>>> 8.9e-4
0.00089
Computers natively represent these numbers using base 2. This means that some numbers can be represented exactly (such as 0.5) while some others are only represented approximately (such as 0.1 or 0.2). Furthermore, this representation uses a fixed number of bits, so there is a limit to the number of digits that can be held.
This is not specific to Python, all computing language have the same issue with floating point numbers.
If we need high precision we can use int numbers and scale them when necessary,
or use decimal.Decimal numbers from the decimal module.
4.3.3. Common numeric operators and functions¶
Syntax |
Description |
|---|---|
|
Adds numbers |
|
Subtracts |
|
Multiplies |
|
Divides |
|
Divides |
|
Produce the modulus (remainder) of dividing |
|
Raise |
|
Negates |
|
Do nothing. It’s sometimes used to clarify. |
|
Return the absolute value of |
|
Return the quotient and the remainder of dividing |
|
Raises |
|
A faster alternative to |
|
Returns |
All the binary numeric operators (+, -, *, /, //, % and **) have an “augmented assignment” version
(+=, -=, *=, /=, //=, %= and **=) where x op= y is logically equivalent to x = x op y.
Numbers can be compared using the following operators:
>and<: strict inequalities==: equality (note the double equal)!=: inequality>=and<=: non-strict inequalities
A comparison results in a Boolean value:
>>> 5 >= 5
True
>>> 3.5 < 2
False
>>> 4 != 2
True
4.4. Strings¶
Strings are represented by the immutable str data type which holds a sequence of characters.
The str data type can be called as a function (str()) to create string objects.
With no arguments, it returns an empty string, with a non string argument it returns the string form of the argument,
and with a string argument it returns the argument itself:
>>> a = "foo"
>>> b = str(a)
>>> a is b
True
Strings literals can be enclosed in matching single quotes (') or double quotes ("):
>>> text = 'This a single-quoted string which can include "double quotes", but \'single\' quotes must be escaped.'
>>> print(text)
This a single-quoted string which can include "double quotes", but 'single' quotes must be escaped.
>>> text = "This a double-quoted string which can include 'single quotes' but \"double\" quotes must be escaped."
>>> print(text)
This a double-quoted string which can include 'single quotes' but "double" quotes must be escaped.
They can also be enclosed in matching groups of three single or double quotes (these are generally referred to as triple-quoted strings):
>>> text = """This is a triple-quoted string in which quotes do not need to be escaped:
... single: '
... double: "
... (and new lines are allowed too)."""
>>> print(text)
This is a triple-quoted string in which quotes do not need to be escaped:
single: '
double: "
(and new lines are allowed too).
The backslash (\) character is used to escape characters that otherwise have a special meaning,
such as newline, backslash itself, or the quote character:
>>> text = "Let's escape a double quote: \", write a real backslash: \\, and escape a new line: \
... (This should not be on a new line.). Now let's write a real new line: \n(This should be on a new line)."
>>> print(text)
Let's escape a double quote: ", write a real backslash: \, and escape a new line: (This should not be on a new line.). Now let's write a real new line:
(This should be on a new line).
Some useful Python string escapes:
escape |
Meaning |
|---|---|
|
backslash |
|
single quote |
|
double quote |
|
linefeed (newline) |
|
tab |
String literals may optionally be prefixed with a letter r or R.
Such strings are called raw strings and use different rules for interpreting backslash escape sequences.
In a raw string, a character following a backslash is included in the string without change,
and all backslashes are left in the string. For example, the string literal r"\n" consists in two characters:
a backslash and a lowercase n:
>>> print(r"\n")
\n
4.4.1. Comparing Strings¶
Strings support the usual comparison operators <, <=, ==, !=, >, >=.
These operators compare strings byte by byte in memory:
>>> "a" > "b"
False
>>> "albert" < "alphonse"
True
The equality operator is == and tests if the right operand has the same value as the left operand:
>>> s1 = "hello"
>>> s2 = "hello"
>>> s1 == s2
True
Warning
We might try to use is to compare two strings:
>>> s1 = "hello"
>>> s2 = "hello"
>>> s1 is s2
True
In this example we created two variables s1 and s2, and it seems that is allows us to compare them.
In fact we do not test the equality of the strings s1 and s2.
We test if the variables s1 and s2 refer to the same object in memory.
See the following example:
>>> s3 = "".join(["h", "e", "l" , "l", "o"])
>>> s1 == s3
True
>>> s1 is s3
False
Note
join is a method that uses a string to join elements in a sequence of strings into a single string.
Here, s3 refers to a string built by joining the individual letters of "hello" together,
inserting the empty string ("") between them.
The string comparison operator is ==, not is (is is for object identity comparison).
So why does it seem to work in the first example?
Python (like Java, .NET, …) uses string pooling / interning.
The interpreter realises that "hello" is the same as "hello",
so it optimizes and uses the same location in memory.
Interned strings speed up string comparisons, which are sometimes a performance bottleneck in applications (such as compilers and dynamic programming language runtimes) that rely heavily on hash tables with string keys. Without interning, checking that two different strings are equal involves examining every character of both strings. This is slow for several reasons:
it is inherently O(n) in the length of the strings (the longer the strings, the longer it takes);
it typically requires reading data from several regions of memory, which take time;
and the reads fills up the processor cache, meaning there is less cache available for other needs.
With interned strings, a simple object identity test suffices after the original intern operation; this is typically implemented as a pointer equality test, normally just a single machine instruction with no memory reference at all.
So, when you have two string literals (words that are literally typed into your program source code, surrounded by quotation marks) in your program that have the same value, the Python compiler will automatically intern the strings, making them both stored at the same memory location. (Note that this doesn’t always happen, and the rules for when this happens are quite convoluted, so please don’t rely on this behavior!)
Note
In Python3, strings are encoded with UTF-8, which means that some characters can be represented by a sequence of two or more bytes.
For instance, the character Å can be represented in UTF-8 encoded bytes in three differents ways:
[0xE2, 0x84, 0xAB], [0xC3, 0x85], [0x41, 0xCC, 0x8A]. So before comparing unicode strings we need to normalize them:
import unicodedata
s = "Génétique"
unicodedata.normalize("NFKC", s)
(More information about normalization is available: https://docs.python.org/3/library/unicodedata.html#unicodedata.normalize.)
The second problem is that the sorting of some characters is language-specific.
For instance in Swedish ä is sorted after z, whereas in German ä is sorted as is though were spelled ae.
To prevent subtle mistakes, Python does not make guesses. It compares using the string memory representation.
This results in a sort order based on Unicode code points.
For English, this amounts to sorting in the order of the ASCII table.
4.4.2. Slicing and Striding Strings¶
Python strings are sequences so we can access any individual item, here characters,
using the square brackets operator [] (which is actually the __getitem__ special method).
The index of the item should be specified between the square brackets.
The indices of the elements start at 0 and go up to the length of the string (not included):
>>> "protein"[0]
'p'
>>> "protein"[3]
't'
But it is also possible to use negative index positions. These count from the last character backwards to the first.
Following an example of index positions for the string s = "Protein".
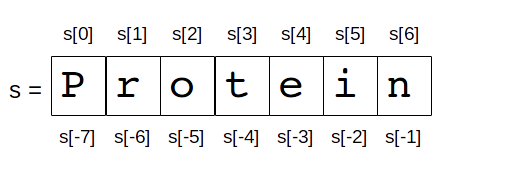
Negative indices are very useful, especially -1 which always gives us access to the last character
in a string (provided the string is not empty).
If one tries to access an item using an index that is too large (even 0, in the case of an empty string)
an IndexError exception is raised:
>>> "protein"[7]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
Now we can access any character of a string, we want to access several characters at once. We call this a slicing operation. The slice operator has three syntaxes:
string[start]string[start:stop]string[start:stop:step]
The start, stop and step must be integers (or variables holding integers).
We already saw the first syntax, which extracts one character.
The second syntax extracts every character starting at index start (included) up to index stop (excluded).
The third syntax is the same as the second except that instead of extracting every characters, every step-th characters are extracted.
If a negative step is given, the slicing is performed and the resulting string is reversed:
>>> s = "Protein"
>>> # the second syntax: [start, stop[
>>> s[2:4]
'ot'
>>> # Note that if we omit the stop index it will default to the end of string
>>> s[2:]
'otein'
>>> # We can also omit the start index, it will then default to 0
>>> s[:2]
'Pr'
>>> s[3:-1]
'tei'
>>> # We can omit both start and stop
>>> z = s[:]
>>> z
'Protein'
>>> # String interning happened:
>>> z is s
True
>>> s[1:-1:2]
'rti'
>>> s[::2]
'Poen'
>>> s[::-2]
'neoP'
>>> s[::-1]
'nietorP'
4.4.3. String operators and methods¶
Since strings are immutable sequences,
all the functions that can be used with immutable sequences can be applied on strings.
This includes:
membership testing with
inconcatenation with
+appending with
+=replication with
*
>>> # Membership
>>> "c" in "gaattc"
True
>>> "z" in "gaattc"
False
>>> "at" in "gaattc"
True
>>> "ta" in "gaattc"
False
>>> # Concatenation
>>> "gaa" + "ttc"
'gaattc'
>>> s = "gaa"
>>> s += "ttc"
>>> s
'gaattc'
>>> # Replication
>>> s = "a" * 10
>>> s
'aaaaaaaaaa'
As strings are sequences they are sized objects. So we can apply the built-in function len on a string.
This will return the number of characters of the string:
>>> len("gaattc")
6
If there are more than two strings to concatenate the join method offers a better option than using +.
The syntax is sep.join(sequence_of_strings), where this method joins the elements of the sequence of strings
in the argument into a single string using the sep string as linking element. For instance:
>>> sequence = ["aa", "bb", "cc"]
>>> "<>".join(sequence)
'aa<>bb<>cc'
>>> "".join(sequence)
'aabbcc'
The join method can be used in combination with the built-in method reversed (which returns a reversed iterator)
to reverse a string:
>>> s = "gaattc"
>>> "".join(reversed(s))
'cttaag'
We have already seen a more concise way to do that:
>>> s = "gaattc"
>>> s[::-1]
'cttaag'
If we are looking for the position of a substring in a string, two methods are available: index and find.
indexreturns the index position of the substring or raises aValueErrorexception on failure.findreturns the index position of the substring or-1on failure.
Both methods take the string to find as their first argument and accept optional arguments. The second argument is the start position in the string being searched, and the third argument is the end position:
>>> "gaattc".find("c")
5
>>> "gaattc".find("c", 0, 4)
-1
>>> "gaattc".index("c")
5
>>> "gaattc".index("c", 0, 4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
For an exhaustive list of the strings methods: https://docs.python.org/3/library/stdtypes.html#string-methods
4.4.4. String formating¶
The format method provide a very powerful and versatile way to create strings using various values.
It returns a new string with the replacement fields in its string replaced with its arguments suitably formatted.
For instance:
>>> name = "EcoR1"
>>> comment = "restriction site 1 for Ecoli"
>>> seq = "gaattc"
>>> fasta = ">{0} {1}\n{2}".format(name, comment, seq)
>>> print(fasta)
>EcoR1 restriction site 1 for Ecoli
gaattc
Each replacement field is identified by a field name in curly braces.
If the field name is simply an integer, it is taken to be index position of one of the arguments passed to str.format.
In the above example, the field whose name was 0 was replaced by the first argument, and so on.
If wee need to include braces inside format strings, we can do so by doubling them up:
>>> "{{{0}}}, {1}.".format("I'm in braces", "I'm not")
"{I'm in braces}, I'm not."
Instead of a number, a field name can be one of the keywords Arguments and Parameters:
>>> fasta = ">{name} {comment}\n{seq}".format(name = "EcoR1",
... comment = "restriction site 1 for Ecoli",
... seq = "gaattc")
>>> print(fasta)
>EcoR1 restriction site 1 for Ecoli
gaattc
It can be also an item in a list:
>>> ecor1 = ["EcoR1", "restriction site 1 for Ecoli", "gaattc"]
>>> fasta = ">{0[0]} {0[1]}\n{0[2]}".format(ecor1)
>>> print(fasta)
>EcoR1 restriction site 1 for Ecoli
gaattc
It can be a value in a dictionary:
>>> ecor1 = {"name": "EcoR1", "seq": "gaattc", "comment": "restriction site 1 for Ecoli"}
>>> fasta = ">{0[name]} {0[comment]}\n{0[seq]}".format(ecor1)
>>> print(fasta)
>EcoR1 restriction site 1 for Ecoli
gaattc
Lists and dictionaries are two widely used containers, that is, data types that contain other data types. We will learn more about lists and dictionaries later.
One very useful way to format string using a dictionary is to Argument unpacking it in the format arguments:
>>> d = {'a': 1, 'b': 2}
>>> "a = {a}, b = {b}".format(**d)
'a = 1, b = 2'
The fields can also be object attributes:
>>> import math
>>> "pi = {0.pi} e = {0.e}".format(math)
'pi = 3.141592653589793 e = 2.718281828459045'
In this case, we used the math module as object.
This module provides, among other things, some mathematical constants.
Starting from Python 3.6, string formatting can be achieved using the f
string prefix instead of the format method. Variables can then be used directly in the fields:
>>> name = "EcoR1"
>>> seq = "gaattc"
>>> comment = "restriction site 1 for Ecoli"
>>> fasta = f">{name} {comment}\n{seq}"
>>> print(fasta)
>EcoR1 restriction site 1 for Ecoli
gaattc
>>> name = "EcoR1"
>>> comment = "restriction site 1 for Ecoli"
>>> seq = "gaattc"
>>> fasta = f">{name} {comment}\n{seq}"
>>> print(fasta)
>EcoR1 restriction site 1 for Ecoli
gaattc
like format method it’s possible to format what is inside bracket for instance:
>>> print(f"{1/3:.2f}")
0.33
: is a separator what is on the left is the value to transform in string what is on right is the way to format this value. For instance f stand for float becaause the value will be a float and .2 means that I want 2 digit after the period.:
>>> print(f"{1/3:.2%}")
33.33%
above the formating is .2% it means that I want 2 digit after period and display the results as percent.
For a full description of strings formatting see https://docs.python.org/3/library/string.html#formatstrings
4.5. Exercices¶
4.5.1. Exercise¶
Assume that we execute the following assignment statements:
width = 17
height = 12.0
For each of the following expressions, write the value of the expression and the type (of the value of the expression) and explain:
width / 2
width // 2
height / 3
1 + 2 * 5
Use the Python interpreter to check your answers.
4.5.2. Exercise¶
Write a function which take a radius as input and return the volume of a sphere:
The volume of a sphere with radius r is 4/3 πr3.
What is the volume of a sphere with radius 5?
Hint: π is in math module, so to access it you need to import the math module
Place the import statement at the top fo your file.
after that, you can use math.pi everywhere in the file like this:
>>> import math
>>>
>>> #do what you need to do
>>> math.pi #use math.pi
Hint: the volume of a sphere with radius 5 is not 392.7 !
4.5.3. Exercise¶
Draw what happens in memory when the following statements are executed:
i = 12
i += 2
and
s = 'gaa'
s = s + 'ttc'
4.5.4. Exercise¶
How to obtain a new sequence which is the 10 times repetition of the this motif : “AGGTCGACCAGATTANTCCG”
4.5.5. Exercise¶
Create a representation in fasta format of following sequence :
Note
A sequence in FASTA format begins with a single-line description, followed by lines of sequence data.
The description line is distinguished from the sequence data by a greater-than (“>”) symbol in the first column.
The word following the “>” symbol is the identifier of the sequence, and the rest of the line is the description (optional).
There should be no space between the “>” and the first letter of the identifier.
The sequence ends
if another line starting with a “>” appears (this indicates the start of another sequence).
or at the end of file.
name = "sp|P60568|IL2_HUMAN"
comment = "Interleukin-2 OS=Homo sapiens GN=IL2 PE=1 SV=1"
sequence = """MYRMQLLSCIALSLALVTNSAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRML
TFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSE
TTFMCEYADETATIVEFLNRWITFCQSIISTLT"""
4.5.6. Exercise¶
For the following exercise use the python file sv40 in fasta which is a python file with the sequence of sv40 in fasta format
already embeded, and use import sv40 in your script to work
(the sv40.py file must be placed in same directory as your own script).
Write a function fasta_2_one_line that return a sequence as a string
without header or any non sequence characters
Note
Pseudocode is an informal high-level description of the operating principle of a computer program or other algorithm.
Pseudocode is a kind of structured english for describing algorithms. It allows the designer to focus on the logic of the algorithm without being distracted by details of language syntax. At the same time, the pseudocode needs to be complete. It describe the entire logic of the algorithm so that implementation becomes a rote mechanical task of translating line by line into source code.
The pseudocode is:
Implement this pseudocode
Note
Your script should start with
from sv40 import *
...
http://www.ncbi.nlm.nih.gov/nuccore/J02400.1
Consider the following restriction enzymes:
BamHI (ggatcc)
EcorI (gaattc)
HindIII (aagctt)
SmaI (cccggg)
For each of them, tell whether it has recogition sites in sv40 (just answer by True or False).
For the enzymes which have a recognition site can you give their positions?
Is there only one site in sv40 per enzyme?
4.5.7. Exercise¶
We want to perform a PCR on sv40. Can you give the length and the sequence of the amplicon?
Write a function which has 3 parameters sequence, primer_1 and primer_2 and returns the amplicon length.
We consider only the cases where primer_1 and primer_2 are present in the sequence.
To simplify the exercise, the 2 primers can be read directly in the sv40 sequence (i.e. no need to reverse-complement).
Test you algorithm with the following primers:
Write the function in pseudocode before implementing it.
4.5.8. Exercise¶
Reverse the following sequence
"TACCTTCTGAGGCGGAAAGA"(don’t compute the complement).Using the shorter string
s = 'gaattc'draw what happens in memory when you reverses.
4.5.9. Exercise¶
il2_human sequence contains 4 cysteins (C) in positions 9, 78, 125, 145.il2_human = 'MYRMQLLSCIALSLALVTNSAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT'
4.5.10. Exercise¶
Write a function which:
takes a sequence as parameter;
computes the GC%;
and returns it;
displays the results as a “human-readable” micro report like this:
'The sv40 is 5243 bp length and has 40.80% gc'.
Use the sv40 sequence to test your function.