5 Collection Data Types¶
5.1 Exercises¶
5.1.1 Exercise¶
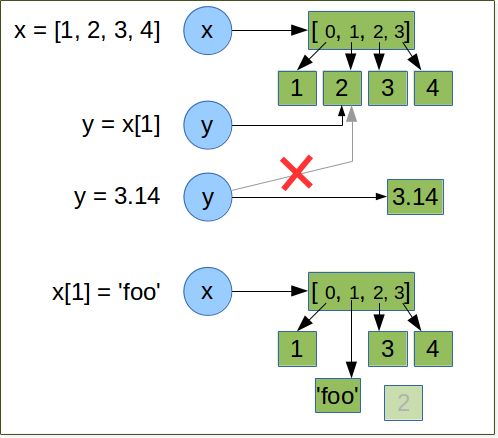
x = [1, 2, 3, 4]
y = x[1]
y = 3.14
x[1] = 'foo'
x = [1, 2, 3, 4]
x += [5, 6]
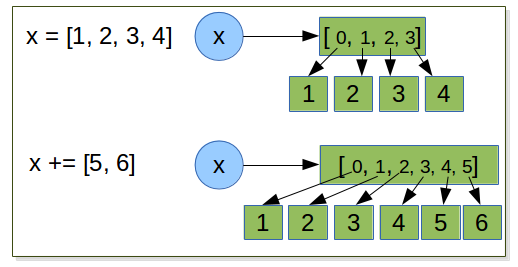
>>> x = [1, 2, 3, 4]
>>> id(x)
139950507563632
>>> x += [5,6]
>>> id(x)
139950507563632
With mutable object like list, when we mutate the object, the state of the object is modified.
But the reference to the object is still unchanged.
Comparison with the exercise on strings and integers:
Since lists are mutable, when += is used, the original list object is modified, so no rebinding of x is necessary.
We can observe this using id() which gives the memory address of an object. This address does not change after the
+= operation.
Note
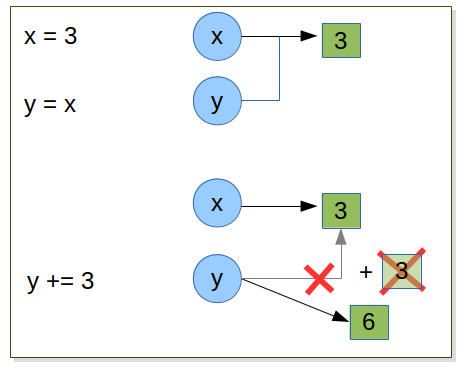
Even the results are the same, there is a subtelty to use augmented operator.
In a operator= b opeeration, Python looks up a’s value only once, so it is potentially faster
than the a = a operator b operation.
Compare
x = 3
y = x
y += 3
x = ?
y = ?
and
x = [1,2]
y = x
y += [3,4]
x = ?
y = ?
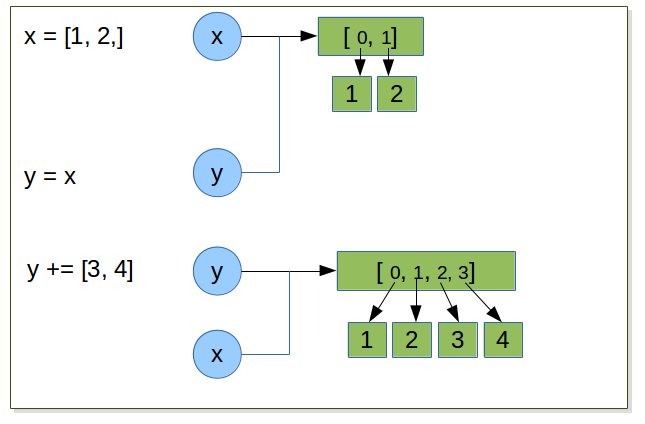
In this example we have two ways to access to the list [1, 2].
If we modify the state of the list itself, but not the references to this object, then the two variables x and y still reference the list containing
[1, 2, 3, 4].
5.1.2 Exercise¶
Note
sum is a function that returns the sum of all the elements of a list.
Without using the Python shell, tell what are the effects of the following statements:
x = [1, 2, 3, 4]
x[3] = -4 # What is the value of x now?
y = sum(x) / len(x) # What is the value of y? Why?
Solution (using the Python shell ;) ):
>>> x = [1, 2, 3, 4]
>>> x[3] = -4
>>> x
[1, 2, 3, -4]
>>> y = sum(x) / len(x)
>>> y
0.5
Here, we compute the mean of the values contained in the list x, after having changed its last element to -4.
5.1.3 Exercise¶
Draw the representation in memory of the x and y variables when the following code is executed:
x = [1, ['a', 'b', 'c'], 3, 4]
y = x[1]
y[2] = 'z'
# What is the value of x?
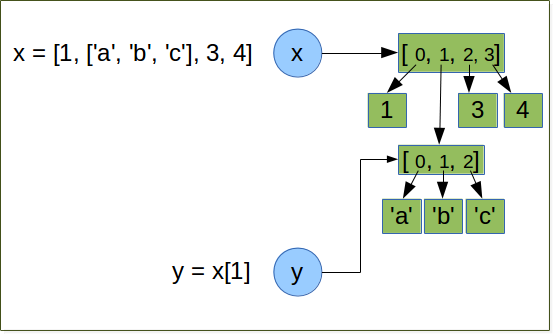

When we execute y = x[1], we create y which references the list ['a', 'b', 'c'].
This list has 2 references on it: y and x[1] .
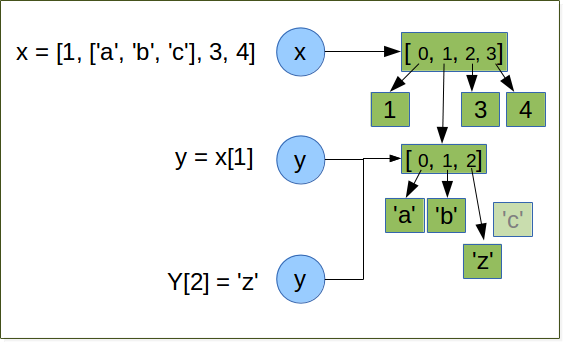
This object is a list so it is a mutable object.
So we can access and modify it by the two ways y or x[1]
x = [1, ['a','b','z'], 3, 4]
5.1.4 Exercise¶
From the list l = [1, 2, 3, 4, 5, 6, 7, 8, 9] generate 2 lists l1 containing all odd values, and l2 all even values.:
l = [1, 2, 3, 4, 5, 6, 7, 8, 9]
l1 = l[::2]
l2 = l[1::2]
or
even = [item for item in l if item % 2 == 0]
odd = [item for item in l if item % 2 != 0]
5.1.5 Exercise¶
Note
A codon is a triplet of nucleotides. A nucleotide can be one of the four letters A, C, G, T
Write a function that returns a list containing strings representing all possible codons.
Write the pseudocode before proposing an implementation.
5.1.5.1 pseudocode:¶
5.1.5.2 first implementation:¶
1
2def all_codons():
3 all_codons = []
4 alphabet = 'acgt'
5 for base_1 in alphabet:
6 for base_2 in alphabet:
7 for base_3 in alphabet:
8 codon = base_1 + base_2 + base_3
9 all_codons.append(codon)
10 return all_codons
python -i codons.py
>>> codons = all_codons()
5.1.5.3 second implementation:¶
Mathematically speaking the generation of all codons can be the Cartesian product
between 3 vectors ‘acgt’.
In python there is a function to do that in itertools module: https://docs.python.org/3/library/itertools.html#itertools.product
1from itertools import product
2
3
4def all_codons():
5 """
6 :return: the 64 codons
7 :rtype: list of string
8 """
9 alphabet = 'acgt'
10 all_codons = [''.join(codon) for codon in product(alphabet, repeat=3)]
11 return all_codons
python -i codons.py
>>> codons = all_codons()
5.1.6 Exercise¶
From a list return a new list without any duplicate, regardless of the order of items. For example:
>>> l = [5,2,3,2,2,3,5,1]
>>> uniqify(l)
>>> [1,2,3,5] #is one of the solutions
5.1.6.1 pseudocode:¶
5.1.6.2 implementation:¶
1def uniqify(l):
2 uniq = []
3 for item in l:
4 if item not in uniq:
5 uniq.append(item)
6 return (uniq)
>>> l=[1,2,3,2,3,4,5,1,2,3,3,2,7,8,9]
>>> uniqify(l)
[1, 2, 3, 4, 5, 7, 8, 9]
5.1.6.3 second implementation:¶
The problem with the first implementation come from the line 4.
Remember that the membership operator uses a linear search for list, which can be slow for very large collections.
If we plan to use uniqify with large list we should find a better algorithm.
In the specification we can read that uniqify can work regardless the order of the resulting list.
So we can use the specificity of set
>>> list(set(l))
5.1.7 Exercise¶
We need to compute the number of occurrences of all kmers of a given length present in a sequence.
Below we propose 2 algorithms.
5.1.7.1 pseudo code 1¶
5.1.7.2 pseudo code 2¶
Note
Computer scientists typically measure an algorithm’s efficiency in terms of its worst-case running time, which is the largest amount of time an algorithm can take given the most difficult input of a fixed size. The advantage to considering the worst case running time is that we are guaranteed that our algorithm will never behave worse than our worst-case estimate.
Big-O notation compactly describes the running time of an algorithm. For example, if your algorithm for sorting an array of n numbers takes roughly n2 operations for the most difficult dataset, then we say that the running time of your algorithm is O(n2). In reality, depending on your implementation, it may be use any number of operations, such as 1.5n2, n2 + n + 2, or 0.5n2 + 1; all these algorithms are O(n2) because big-O notation only cares about the term that grows the fastest with respect to the size of the input. This is because as n grows very large, the difference in behavior between two O(n2) functions, like 999 · n2 and n2 + 3n + 9999999, is negligible when compared to the behavior of functions from different classes, say O(n2) and O(n6). Of course, we would prefer an algorithm requiring 1/2 · n2 steps to an algorithm requiring 1000 · n2 steps.
When we write that the running time of an algorithm is O(n2), we technically mean that it does not grow faster than a function with a leading term of c · n2, for some constant c. Formally, a function f(n) is Big-O of function g(n), or O(g(n)), when f(n) <= c · g(n) for some constant c and sufficiently large n.
For more on Big-O notation, see A http://rob-bell.net/2009/06/a-beginners-guide-to-big-o-notation/Beginner’s.
Compare the pseudocode of each of them and implement the fastest one.
"""gtcagaccttcctcctcagaagctcacagaaaaacacgctttctgaaagattccacactcaatgccaaaatataccacag
gaaaattttgcaaggctcacggatttccagtgcaccactggctaaccaagtaggagcacctcttctactgccatgaaagg
aaaccttcaaaccctaccactgagccattaactaccatcctgtttaagatctgaaaaacatgaagactgtattgctcctg
atttgtcttctaggatctgctttcaccactccaaccgatccattgaactaccaatttggggcccatggacagaaaactgc
agagaagcataaatatactcattctgaaatgccagaggaagagaacacagggtttgtaaacaaaggtgatgtgctgtctg
gccacaggaccataaaagcagaggtaccggtactggatacacagaaggatgagccctgggcttccagaagacaaggacaa
ggtgatggtgagcatcaaacaaaaaacagcctgaggagcattaacttccttactctgcacagtaatccagggttggcttc
tgataaccaggaaagcaactctggcagcagcagggaacagcacagctctgagcaccaccagcccaggaggcacaggaaac
acggcaacatggctggccagtgggctctgagaggagaaagtccagtggatgctcttggtctggttcgtgagcgcaacaca"""
In the first algorithm.
sequence length)Compute the 6 mers occurrences of the sequence above, and print each 6mer and it’s occurrence one per line.
1
2def get_kmer_occurences(seq, kmer_len):
3 """
4 return a list of tuple
5 each tuple contains a kmers present in seq and its occurence
6 """
7 # Counter dictionary (keys will be kmers, values will be counts)
8 kmers = {}
9 stop = len(seq) - kmer_len
10 for i in range(stop + 1):
11 # Extract kmer starting at position i
12 kmer = seq[i: i + kmer_len]
13 # Increment the count for kmer
14 # or create the entry the first time this kmer is seen
15 # using default value 0, plus 1
16 kmers[kmer] = kmers.get(kmer, 0) + 1
17 # pairs (kmer, count)
18 return kmers.items()
>>> s = """"gtcagaccttcctcctcagaagctcacagaaaaacacgctttctgaaagattccacactcaatgccaaaatataccacag
... gaaaattttgcaaggctcacggatttccagtgcaccactggctaaccaagtaggagcacctcttctactgccatgaaagg
... aaaccttcaaaccctaccactgagccattaactaccatcctgtttaagatctgaaaaacatgaagactgtattgctcctg
... atttgtcttctaggatctgctttcaccactccaaccgatccattgaactaccaatttggggcccatggacagaaaactgc
... agagaagcataaatatactcattctgaaatgccagaggaagagaacacagggtttgtaaacaaaggtgatgtgctgtctg
... gccacaggaccataaaagcagaggtaccggtactggatacacagaaggatgagccctgggcttccagaagacaaggacaa
... ggtgatggtgagcatcaaacaaaaaacagcctgaggagcattaacttccttactctgcacagtaatccagggttggcttc
... tgataaccaggaaagcaactctggcagcagcagggaacagcacagctctgagcaccaccagcccaggaggcacaggaaac
... acggcaacatggctggccagtgggctctgagaggagaaagtccagtggatgctcttggtctggttcgtgagcgcaacaca"""
>>> s = s.replace('\n', '')
>>> kmers = get_kmer_occurences(s, 6)
>>> for kmer in kmers:
>>> print(kmer[0], '..', kmer[1])
gcagag .. 2
aacttc .. 1
gcaact .. 1
aaatat .. 2
5.1.7.3 bonus:¶
Print the kmers by ordered by occurrences.
1import collections
2from operator import itemgetter
3
4
5def get_kmer_occurences(seq, kmer_len):
6 """
7 return a list of tuple
8 each tuple contains a kmers present in seq and its occurence
9 """
10 kmers = collections.defaultdict(int)
11 stop = len(seq) - kmer_len
12 for i in range(stop + 1):
13 kmer = seq[i: i + kmer_len]
14 kmers[kmer] += 1
15 kmers = kmers.items()
16 kmers.sort(key=itemgetter(1), reverse=True)
17 return kmers
>>> s = """"gtcagaccttcctcctcagaagctcacagaaaaacacgctttctgaaagattccacactcaatgccaaaatataccacag
... gaaaattttgcaaggctcacggatttccagtgcaccactggctaaccaagtaggagcacctcttctactgccatgaaagg
... aaaccttcaaaccctaccactgagccattaactaccatcctgtttaagatctgaaaaacatgaagactgtattgctcctg
... atttgtcttctaggatctgctttcaccactccaaccgatccattgaactaccaatttggggcccatggacagaaaactgc
... agagaagcataaatatactcattctgaaatgccagaggaagagaacacagggtttgtaaacaaaggtgatgtgctgtctg
... gccacaggaccataaaagcagaggtaccggtactggatacacagaaggatgagccctgggcttccagaagacaaggacaa
... ggtgatggtgagcatcaaacaaaaaacagcctgaggagcattaacttccttactctgcacagtaatccagggttggcttc
... tgataaccaggaaagcaactctggcagcagcagggaacagcacagctctgagcaccaccagcccaggaggcacaggaaac
... acggcaacatggctggccagtgggctctgagaggagaaagtccagtggatgctcttggtctggttcgtgagcgcaacaca"""
>>> s = s.replace('\n', '')
>>> kmers = get_kmer_occurences(s, 6)
>>> for kmer, occ in kmers:
>>> print kmer, '..', occ
cacagg .. 4
aggaaa .. 4
ttctga .. 3
ccagtg .. 3
5.1.8 Exercise¶
5.1.8.1 pseudocode:¶
1
2def rev_comp(seq):
3 """
4 return the reverse complement of seq
5 the sequence must be in lower case
6 """
7 complement = {'a': 't',
8 'c': 'g',
9 'g': 'c',
10 't': 'a'}
11 rev_seq = seq[::-1]
12 rev_comp = ''
13 for nt in rev_seq:
14 rev_comp += complement[nt]
15 return rev_comp
- ::
>>> from rev_comp import rev_comp >>> >>> seq = 'acggcaacatggctggccagtgggctctgagaggagaaagtccagtggatgctcttggtctggttcgtgagcgcaacaca' >>> print rev_comp(seq) tgtgttgcgctcacgaaccagaccaagagcatccactggactttctcctctcagagcccactggccagccatgttgccgt
5.1.8.2 other solution¶
Python provides an interesting method for our problem.
The translate method works on a string and needs a parameter which is an object
that can do the correspondence between characters in the old string and the new one.
maketrans is a function in module string that allows us to build this object.
maketrans takes two strings as arguments, the first one contains the characters
to change, the second contains the corresponding characters in the new string.
Thus the two strings must have the same length. The correspondence between
the characters to change and their new values is made in function of their position.
The first character of the first string will be replaced by the first character of the second string,
the second character of the first string will be replaced by the second character of the second string, and so on.
So we can write the reverse complement without a loop.
1
2
3def rev_comp(seq):
4 """
5 return the reverse complement of seq
6 the case is respect but if the sequence mix upper and lower case the function will failed
7 """
8 reverse = seq[::-1]
9 direct = 'acgtATCG'
10 comp = 'tgcaTGCA'
11 table = str.maketrans(direct, comp)
12 rev_comp = reverse.translate(table)
13 return rev_comp
- ::
>>> from rev_comp2 import rev_comp >>> >>> seq = 'acggcaacatggctggccagtgggctctgagaggagaaagtccagtggatgctcttggtctggttcgtgagcgcaacaca' >>> print rev_comp(seq) tgtgttgcgctcacgaaccagaccaagagcatccactggactttctcctctcagagcccactggccagccatgttgccgt
5.1.9 Exercise¶
We have a collection of restriction enzymes. We decide to implement enzymes as tuples with the following structure (“name”, “comment”, “sequence”, “cut”, “end”)
ecor1 = ("EcoRI", "Ecoli restriction enzime I", "gaattc", 1, "sticky")
ecor5 = ("EcoRV", "Ecoli restriction enzime V", "gatatc", 3, "blunt")
bamh1 = ("BamHI", "type II restriction endonuclease from Bacillus amyloliquefaciens ", "ggatcc", 1, "sticky")
hind3 = ("HindIII", "type II site-specific nuclease from Haemophilus influenzae", "aagctt", 1 , "sticky")
taq1 = ("TaqI", "Thermus aquaticus", "tcga", 1 , "sticky")
not1 = ("NotI", "Nocardia otitidis", "gcggccgc", 2 , "sticky")
sau3a1 = ("Sau3aI", "Staphylococcus aureus", "gatc", 0 , "sticky")
hae3 = ("HaeIII", "Haemophilus aegyptius", "ggcc", 2 , "blunt")
sma1 = ("SmaI", "Serratia marcescens", "cccggg", 3 , "blunt")
We have the 2 dna fragments:
dna_1 = """tcgcgcaacgtcgcctacatctcaagattcagcgccgagatccccgggggttgagcgatccccgtcagttggcgtgaattcag
cagcagcgcaccccgggcgtagaattccagttgcagataatagctgatttagttaacttggatcacagaagcttccaga
ccaccgtatggatcccaacgcactgttacggatccaattcgtacgtttggggtgatttgattcccgctgcctgccagg"""
dna_2 = """gagcatgagcggaattctgcatagcgcaagaatgcggccgcttagagcgatgctgccctaaactctatgcagcgggcgtgagg
attcagtggcttcagaattcctcccgggagaagctgaatagtgaaacgattgaggtgttgtggtgaaccgagtaag
agcagcttaaatcggagagaattccatttactggccagggtaagagttttggtaaatatatagtgatatctggcttg"""
- In a file <my_file.py>
Write a function seq_one_line which take a multi lines sequence and return a sequence in one line.
Write a function enz_filter which take a sequence and a list of enzymes and return a new list containing the enzymes which have a binding site in the sequence
open a terminal with the command python -i <my_file.py>
copy paste the enzymes and dna fragments
use the functions above to compute the enzymes which cut the dna_1 apply the same functions to compute the enzymes which cut the dna_2 compute the difference between the enzymes which cut the dna_1 and enzymes which cut the dna_2
1
2
3def one_line(seq):
4 return seq.replace('\n', '')
5
6def enz_filter(enzymes, dna):
7 cuting_enz = []
8 for enz in enzymes:
9 if enz[2] in dna:
10 cuting_enz.append(enz)
11 return cuting_enz
12
from enzyme_1 import *
enzymes = [ecor1, ecor5, bamh1, hind3, taq1, not1, sau3a1, hae3, sma1]
dna_1 = one_line(dna_1)
dans_2 = one_line(dna_2)
enz_1 = enz_filter(enzymes, dna_1)
enz_2 = enz_filter(enzymes, dna_2)
enz1_only = set(enz_1) - set(enz_2)
With this algorithm we find if an enzyme cut the dna but we cannot find all cuts in the dna for an enzyme.
enzymes = [ecor1, ecor5, bamh1, hind3, taq1, not1, sau3a1, hae3, sma1]
digest_1 = []
for enz in enzymes:
print enz.name, dna_1.count(enz.sequence)
The latter algorithm displays the number of occurrence of each enzyme, But we cannot determine the position of every sites. We will see how to do this later.
There is another kind of tuple which allows to access to items by index or name. This data collection is called NamedTuple. The NamedTuple are not accessible directly they are in collections package, so we have to import it before to use it. We also have to define which name correspond to which item:
import collections
RestrictEnzyme = collections.namedtuple("RestrictEnzyme", ("name", "comment", "sequence", "cut", "end"))
Then we can use this new kind of tuple:
ecor1 = RestrictEnzyme("EcoRI", "Ecoli restriction enzime I", "gaattc", 1, "sticky")
ecor5 = RestrictEnzyme("EcoRV", "Ecoli restriction enzime V", "gatatc", 3, "blunt")
bamh1 = RestrictEnzyme("BamHI", "type II restriction endonuclease from Bacillus amyloliquefaciens ", "ggatcc", 1, "sticky")
hind3 = RestrictEnzyme("HindIII", "type II site-specific nuclease from Haemophilus influenzae", "aagctt", 1 , "sticky")
taq1 = RestrictEnzyme("TaqI", "Thermus aquaticus", "tcga", 1 , "sticky")
not1 = RestrictEnzyme("NotI", "Nocardia otitidis", "gcggccgc", 2 , "sticky")
sau3a1 = RestrictEnzyme("Sau3aI", "Staphylococcus aureus", "gatc", 0 , "sticky")
hae3 = RestrictEnzyme("HaeIII", "Haemophilus aegyptius", "ggcc", 2 , "blunt")
sma1 = RestrictEnzyme("SmaI", "Serratia marcescens", "cccggg", 3 , "blunt")
The code must be adapted as below
1
2
3def one_line(seq):
4 return seq.replace('\n', '')
5
6def enz_filter(enzymes, dna):
7 cuting_enz = []
8 for enz in enzymes:
9 if enz.sequence in dna:
10 cuting_enz.append(enz)
11 return cuting_enz
12
5.1.10 Exercise¶
given the following dict :
d = {1 : 'a', 2 : 'b', 3 : 'c' , 4 : 'd'}
We want to obtain a new dict with the keys and the values inverted so we will obtain:
inverted_d {'a': 1, 'c': 3, 'b': 2, 'd': 4}
solution
inverted_d = {}
for key in d.keys():
inverted_d[d[key]] = key
solution
inverted_d = {}
for key, value in d.items():
inverted_d[value] = key
solution
inverted_d = {v : k for k, v in d.items()}