4 Data Types¶
4.1 Exercices¶
4.1.1 Exercise¶
Assume that we execute the following assignment statements:
width = 17
height = 12.0
For each of the following expressions, write the value of the expression and the type (of the value of the expression) and explain.
width / 2
width // 2
height / 3
1 + 2 * 5
Use the Python interpreter to check your answers.
>>> width = 17
>>> height = 12.0
>>> width / 2
8.5
>>> width // 2
8
>>> # // is to perform an euclidean division
>>> height / 3
4.0
>>> 1 + 2 * 5
11
4.1.2 Exercise¶
Write a function which take a radius as input and return the volume of a sphere:
The volume of a sphere with radius r is 4/3 πr3.
What is the volume of a sphere with radius 5?
Hint: π is in math module, so to access it you need to import the math module
Place the import statement at the top fo your file.
after that, you can use math.pi everywhere in the file like this:
>>> import math
>>>
>>> #do what you need to do
>>> math.pi #use math.pi
1import math
2
3def vol_of_sphere(radius):
4 """
5 compute the volume of sphere of a given radius
6 work only in python3
7 """
8
9 vol = 4 / 3 * math.pi * pow(radius, 3)
10 return vol
11
12
13def vol_of_sphere_python2(radius):
14 """
15 compute the volume of sphere of a given radius
16 work with python2 and 3
17 """
18
19 vol = float(4) / float(3) * float(math.pi) * pow(radius, 3)
20 return vol
python -i volume_of_sphere.py
>>> vol_of_sphere(5)
523.5987755982989
4.1.3 Exercise¶
Draw what happen in memory when the following statements are executed:
i = 12
i += 2
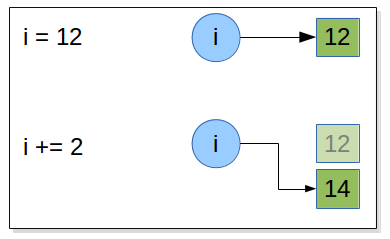
>>> i = 12
>>> id(i)
33157200
>>> i += 2
>>> id(i)
33157152
and
s = 'gaa'
s = s + 'ttc'

>>> s = 'gaa'
>>> id(s)
139950507582368
>>> s = s+ 'ttc'
>>> s
'gaattc'
>>> id(s)
139950571818896
when an augmented assignment operator is used on an immutable object is that
the operation is performed,
and an object holding the result is created
and then the target object reference is re-bound to refer to the result object rather than the object it referred to before.
So, in the preceding case when the statement i += 2 is encountered, Python computes 1 + 2 , stores
the result in a new int object, and then rebinds i to refer to this new int . And
if the original object a was referring to has no more object references referring
to it, it will be scheduled for garbage collection. The same mechanism is done with all immutable object included strings.
4.1.4 Exercise¶
- how to obtain a new sequence which is the 10 times repetition of the this motif“AGGTCGACCAGATTANTCCG”::
>>> s = "AGGTCGACCAGATTANTCCG" >>> s10 = s * 10
4.1.5 Exercise¶
create a representation in fasta format of following sequence :
Note
A sequence in FASTA format begins with a single-line description, followed by lines of sequence data. The description line is distinguished from the sequence data by a greater-than (“>”) symbol in the first column. The word following the “>” symbol is the identifier of the sequence, and the rest of the line is the description (optional). There should be no space between the “>” and the first letter of the identifier. The sequence ends if another line starting with a “>” appears; this indicates the start of another sequence.
name = "sp|P60568|IL2_HUMAN"
comment = "Interleukin-2 OS=Homo sapiens GN=IL2 PE=1 SV=1"
sequence = """MYRMQLLSCIALSLALVTNSAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRML
TFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSE
TTFMCEYADETATIVEFLNRWITFCQSIISTLT"""
>>> s = ">" + name + " " + comment + '\n' + sequence
or
>>> s = ">{name} {comment}\n{sequence}".format(id=id, comment=comment, sequence=sequence)
or
>>> s = f">{name} {comment}\n{sequence}"
4.1.6 Exercise¶
For the following exercise use the python file sv40 in fasta which is a python file with the sequence of sv40 in fasta format
already embeded, and use python -i sv40_file.py to work.
How long is the sv40 in bp? Hint : the fasta header is 61bp long. (http://www.ncbi.nlm.nih.gov/nuccore/J02400.1)
pseudocode
write a function fasta_to_one_line that return a sequence as a string
without header or any non sequence characters
pseudocode:
1
2def fasta_to_one_line(seq):
3 header_end_at = seq.find('\n')
4 seq = seq[header_end_at + 1:]
5 seq = seq.replace('\n', '')
6 return seq
7
python
>>> import sv40_file
>>> import fasta_to_one_line
>>>
>>> sv40_seq = fasta_to_one_line(sv40_file.sv40_fasta)
>>> print len(sv40_seq)
5243
Consider the following restriction enzymes:
BamHI (ggatcc)
EcorI (gaattc)
HindIII (aagctt)
SmaI (cccggg)
For each of them, tell whether it has recogition sites in sv40 (just answer by True or False).
>>> "ggatcc".upper() in sv40_sequence
True
>>> "gaattc".upper() in sv40_sequence
True
>>> "aagctt".upper() in sv40_sequence
True
>>> "cccggg".upper() in sv40_sequence
False
For the enzymes which have a recognition site can you give their positions?
>>> sv40_sequence = sv40_sequence.lower()
>>> sv40_sequence.find("ggatcc")
2532
>>> # remind the string are numbered from 0
>>> 2532 + 1
2533
>>> # the recognition motif of BamHI start at 2533
>>> sv40_sequence.find("gaattc")
1781
>>> # EcorI -> 1782
>>> sv40_sequence.find("aagctt")
1045
>>> # HindIII -> 1046
Is there only one site in sv40 per enzyme?
The find method gives the index of the first occurrence or -1 if the substring is not found.
So we can not determine the number of occurrences of a site only with the find method.
We can know how many sites are present with the count method.
>>> sv40_seq.count("ggatcc")
1
>>> sv40_seq.count("gaattc")
1
>>> sv40_seq.count("aagctt")
6
>>> sv40_seq.count("cccggg")
0
We will see how to determine all occurrences of restriction sites when we learn looping and conditions.
4.1.7 Exercise¶
We want to perform a PCR on sv40. Can you give the length and the sequence of the amplicon?
Write a function which has 3 parameters sequence, primer_1 and primer_2 and returns the amplicon length.
We consider only the cases where primer_1 and primer_2 are present in the sequence.
To simplify the exercise, the 2 primers can be read directly in the sv40 sequence (i.e. no need to reverse-complement).
Test you algorithm with the following primers:
Write the function in pseudocode before implementing it.
1
2def amplicon_len(seq, primer_1, primer_2):
3 """
4 given primer_1 and primer_2
5 return the lenght of the amplicon
6 primer_1 and primer_2 ar present and in this order
7 in sequence
8 """
9 primer_1 = primer_1.upper()
10 primer_2 = primer_2.upper()
11 sequence = sequence.upper()
12 pos_1 = sv40_sequence.find(primer_1)
13 pos_2 = sv40_sequence.find(primer_2)
14 amplicon_len = pos_2 + len(primer_2) - pos_1
15 return amplicon_len
>>> import sv40
>>> import fasta_to_one_line
>>>
>>> sequence = fasta_to_one_line(sv40)
>>> print amplicon_len(sequence, first_primer, second_primer )
199
4.1.8 Exercise¶
Reverse the following sequence
"TACCTTCTGAGGCGGAAAGA"(don’t compute the complement).
>>> "TACCTTCTGAGGCGGAAAGA"[::-1]
# or
>>> s = "TACCTTCTGAGGCGGAAAGA"
>>> l = list(s)
# take care reverse() reverse a list in place (the method do a side effect and return None )
# so if you don't have a object reference on the list you cannot get the reversed list!
>>> l.reverse()
>>> print l
>>> ''.join(l)
# or
>>> rev_s = reversed(s)
''.join(rev_s)
The most efficient way to reverse a string or a list is the way using the slice.
4.1.9 Exercise¶
il2_human sequence contains 4 cysteins (C) in positions 9, 78, 125, 145.We have to take care of the difference between Python string numbering and usual position numbering:
il2_human = 'MYRMQLLSCIALSLALVTNSAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT'
head = il2_human[:77]
body = il2_human[77:125]
tail = il2_human[126:]
body_mutate = body.replace('C', 'S')
il2_mutate = head + body_mutate + tail
4.1.10 Exercise¶
Write a function which:
takes a sequence as parameter;
computes the GC%;
and returns it;
displays the results as a “human-readable” micro report like this:
'The sv40 is 5243 bp length and has 40.80% gc'.
Use the sv40 sequence to test your function.
1
2def gc_percent(seq):
3 """
4 :param seq: The nucleic sequence to compute
5 :type seq: string
6 :return: the percent of GC in the sequence
7 :rtype: float
8 """
9 seq = seq.upper()
10 gc_pc = float(seq.count('G') + seq.count('C')) / float(len(seq))
11 return gc_pc
>>> import sv40
>>> import fasta_to_one_line
>>> import gc_percent
>>>
>>> sequence = fasta_to_one_line(sv40)
>>> gc_pc = gc_percent(sequence)
>>> report = "The sv40 is {0} bp length and has {1:.2%} gc".format(len(sequence), gc_pc)
>>> print report
'The sv40 is 5243 bp length and has 40.80% gc'